
Vector database production decisions are usually made too early — before you know your query volume, your filtering requirements, or whether embedding search is even the bottleneck. I’ve seen teams spin up Pinecone on day one of a RAG prototype and then watch it sit mostly idle while generating a $400 monthly bill for a system serving 50 internal users.
This article is about how I think about the choice. Not as a product comparison, but as a production decision with real operational cost on both sides.
What Vector Databases Actually Solve
A vector database stores high-dimensional embeddings and lets you retrieve the most semantically similar ones to a query. That’s the core job. Dedicated vector stores like Pinecone, Weaviate, and Qdrant were built to do this at scale — with approximate nearest neighbor (ANN) indexes optimized for latency, support for metadata filtering alongside vector similarity, and multi-tenant isolation.
The problem: most of those capabilities only matter past a certain threshold. Under that threshold, you’re paying operational overhead for infrastructure you don’t need.
The question is where the threshold is. For most production RAG systems I’ve worked on, it’s higher than people assume.
pgvector Is Good Enough More Often Than Not
PostgreSQL with the pgvector extension supports storing embeddings as a native column type and querying by cosine similarity, L2 distance, or inner product. You get vector search inside your existing database — same connection pool, same query engine, same backup infrastructure.
I built the retrieval layer of a document Q&A system on pgvector. The corpus was ~80,000 chunks. Median query latency: 38ms without an index, 12ms with an IVFFlat index on the embedding column. That system never needed anything else.
The tradeoff: pgvector’s ANN index options are more limited than Qdrant’s HNSW implementation, and exact nearest neighbor search slows down past a few hundred thousand rows without careful index tuning. You also can’t push filtering into the vector search the way dedicated stores can — you filter in SQL before or after the similarity query, which means suboptimal performance if you’re filtering on low-selectivity conditions.
Those limitations matter at a certain scale. At 80,000 chunks with straightforward metadata filtering, they didn’t matter at all.
If you already run PostgreSQL in production, pgvector is the default starting point. Migrating to a dedicated vector store later is a clear decision you can make with real data. Skipping straight to Pinecone on day one is a bet that you’ll need it — and most teams lose that bet.
The Real Cost of Running a Dedicated Vector Store in Production
Pinecone serverless starts cheap, but the bill grows non-linearly with upserts and query volume. Weaviate and Qdrant require you to run infrastructure — either a managed service or self-hosted, both of which come with operational weight.
I’ve tracked costs across a few vector database production deployments where the vector store was a separate service:
- A customer support RAG system with ~200,000 chunks and ~1,500 daily queries ran at ~$180/month on Pinecone’s serverless tier. The same workload on a PostgreSQL instance with pgvector cost ~$40/month (absorbed into an existing RDS instance).
- A document search system with 2M+ chunks and complex multi-field metadata filtering ran on Qdrant — self-hosted on a single 16GB VM. It performed well. But it also required a dedicated DevOps budget to maintain, monitor, and upgrade. That’s not a line item that shows up in a benchmarking post.
The hidden cost people underestimate is operational complexity. A dedicated vector store is another service with its own SDK, its own authentication model, its own failure modes, and its own upgrade cycle. I’ve written about this pattern in the context of Azure AI cost optimization — the line item on the bill is rarely the whole story.
For most teams running their first or second RAG system, this overhead isn’t justified.
When Retrieval Quality Becomes the Constraint
A common mistake: optimizing the vector store before understanding whether retrieval is even the bottleneck.
Bad retrieval is usually a chunking problem or an embedding model problem. Switching from pgvector to Pinecone doesn’t fix either of those. I’ve diagnosed systems where teams were convinced their vector store wasn’t returning relevant results — when the actual issue was chunks that were too large, metadata that wasn’t being filtered correctly, or an embedding model that hadn’t been evaluated against their domain vocabulary.
Fine-tuning vs. RAG covers this at the model layer. The same diagnostic mindset applies to retrieval infrastructure: measure before you upgrade.
If you’re seeing low-quality top-k results, check these before considering a vector store migration:
- Are your chunks coherent units of meaning, or arbitrary 512-token windows?
- Have you evaluated your embedding model on queries representative of your actual users?
- Is your similarity threshold too permissive — returning semantically distant results because the top-k cutoff is too generous?
A dedicated vector store won’t fix bad embeddings. It will serve them faster.
There’s also the retrieval evaluation gap to consider. Most teams ship a RAG system without a formal retrieval evaluation suite. They judge quality informally — a few test queries that feel like they work. That’s not enough signal to know whether your vector store is the constraint. Before I touch infrastructure, I want to see recall@k measured against a labeled sample of real queries. If recall is low, I start with chunk size and embedding model. Infrastructure changes come last.
The teams I’ve seen switch to a dedicated vector database for “better retrieval” and not see improvement almost always had this problem. The move felt like progress. It wasn’t.
When You Genuinely Need a Dedicated Vector Store
There are real cases where pgvector doesn’t cut it. They’re specific, and you’ll recognize them when you have them.
Corpus size past ~5M chunks. pgvector’s IVFFlat index degrades meaningfully at this scale. Qdrant’s HNSW index maintains sub-100ms p95 latency in benchmarks up to hundreds of millions of vectors. If you’re indexing a large document archive or a product catalog at enterprise scale, you’ll hit this ceiling.
Complex filtering alongside vector search. Dedicated stores can execute hybrid queries — vector similarity filtered by metadata — within a single index scan. pgvector requires pre-filtering or post-filtering in SQL, which means either retrieving too many candidates or missing relevant results under tight selectivity. If your query pattern is “find similar documents AND authored by X AND tagged with Y AND in status Z,” a dedicated store handles this more cleanly.
Multi-tenancy with strict isolation. Pinecone namespaces and Qdrant collections give you tenant isolation without query-time filtering on a tenant_id column. For systems where data isolation is a compliance requirement rather than a nice-to-have, that architectural separation matters.
High write volume. If you’re indexing at high throughput — streaming new content continuously — dedicated stores handle concurrent writes with less contention than pgvector’s index locking behavior. Batch ingestion every few hours? Not an issue. Continuous streaming ingest at thousands of vectors per second? That’s where dedicated infrastructure earns its cost.
The pattern: every justification is a concrete, present-tense constraint. Not “we might have enterprise customers someday.” A real load profile, a real compliance requirement, a real query pattern you’ve already measured.

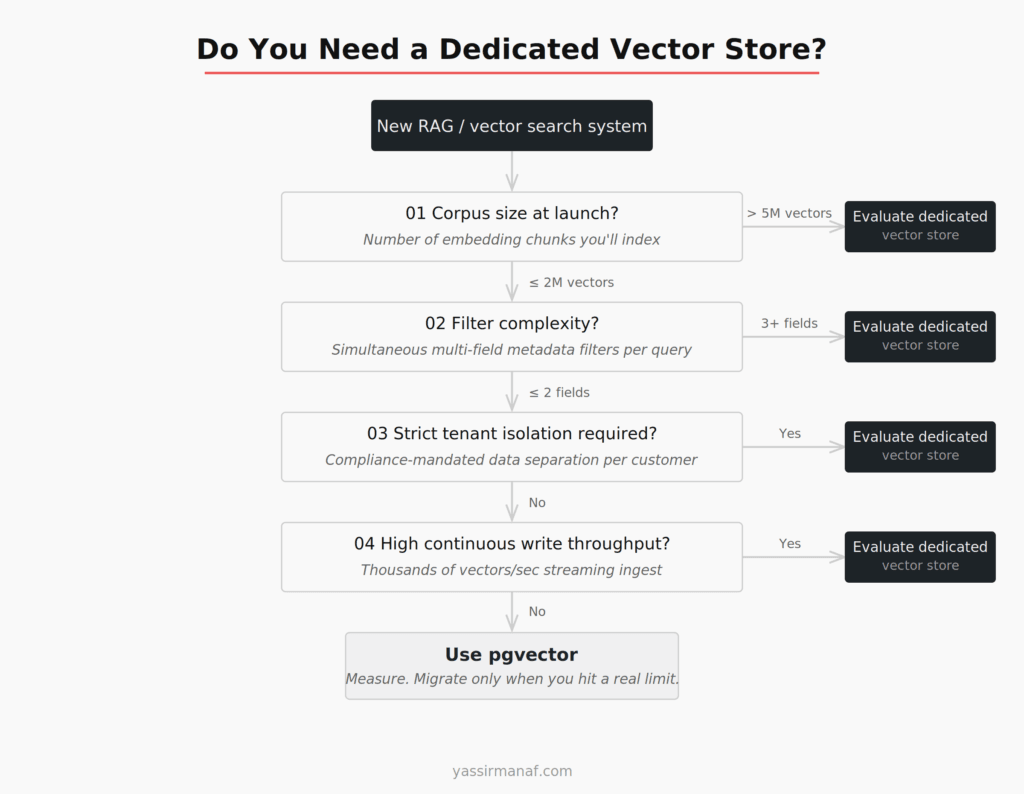
The Decision Framework I Use
Before recommending a dedicated vector store on any project, I ask four questions:
1. How many vectors will you index at launch? Under 2M: start with pgvector. Over 5M: evaluate dedicated options. Between 2M and 5M: benchmark your actual query pattern before deciding.
2. How complex is your filter logic? If every query filters on 3+ metadata fields simultaneously, dedicated stores offer cleaner performance. Single-field filtering or no filtering: pgvector handles it.
3. Do you have strict tenant isolation requirements? Compliance-driven isolation is one of the few arguments for a dedicated store even at modest scale. Row-level security in PostgreSQL can handle soft multi-tenancy. It can’t replace the architectural separation that some compliance frameworks require.
4. What does your team already operate? Adding Qdrant to a stack where nobody has operated it before is a real cost. If your team already runs Weaviate, the marginal overhead is different. When I look at AI observability in production, the same calculus applies — familiarity with your tooling reduces incident response time.
The default answer for a new RAG system is pgvector. The burden of proof is on switching — not on staying.
One more thing I track: the migration path. Moving from pgvector to a dedicated store later is a data pipeline change — export embeddings, re-ingest, update your retrieval client. Annoying but straightforward. Moving the other direction — from a dedicated store back to pgvector — is less common but equally tractable. Neither direction is a trap. That reversibility is part of why starting with pgvector is the right default: you’re not locked in.
What I’d Do Right Now
If you’re building your first RAG system: use pgvector. Add an IVFFlat or HNSW index when your corpus exceeds 500,000 chunks. Measure query latency in your actual production environment before you even look at alternatives. Vector database production costs are almost always dominated by operations and maintenance, not the query bill.
If you’re already running a dedicated vector store at low scale: calculate what you’re spending versus what pgvector on your existing database would cost. The migration is mostly a data pipeline change. It’s not as painful as it sounds.
If you’re hitting genuine scale — millions of vectors, high write throughput, complex multi-tenant filtering — then evaluate Qdrant (self-hosted, strong HNSW performance) or Pinecone (managed, lowest operational overhead) based on your team’s capacity to operate infrastructure. The LLM in production challenges at scale are real, and the vector layer is just one part of the system that needs to hold up.
The question worth asking isn’t “which vector database is best?” Most benchmarks answer that question without accounting for operational cost, team familiarity, or the specific query patterns that actually matter to your users.
The right question is: “do I need a vector database at all?” For most teams, the answer is no — not yet, maybe never.
Start there.
What’s your vector store setup in production? I’d be curious what pushed you to a dedicated solution if you made that choice. Find me on LinkedIn.
Leave a Reply