I built a production NLP pipeline with Rasa in 2019. Not a demo — a deployed assistant handling real user requests, integrated with backend services, with SLAs that stakeholders tracked weekly. Rasa production NLP is not glamorous work. It’s intent taxonomy decisions, confidence threshold tuning, and three hours debugging why a single entity extractor fails on hyphenated input.
I’m glad I did it. The discipline it forced is exactly what most LLM-based systems skip — and then spend months debugging in production.
This isn’t a case against LLMs. I build with them now and the productivity gain is real. But there’s a category of hard-won understanding that Rasa extracts from you through constraint, and that understanding doesn’t transfer automatically when you switch tools. It has to be rebuilt deliberately.
What Rasa Production NLP Actually Looks Like
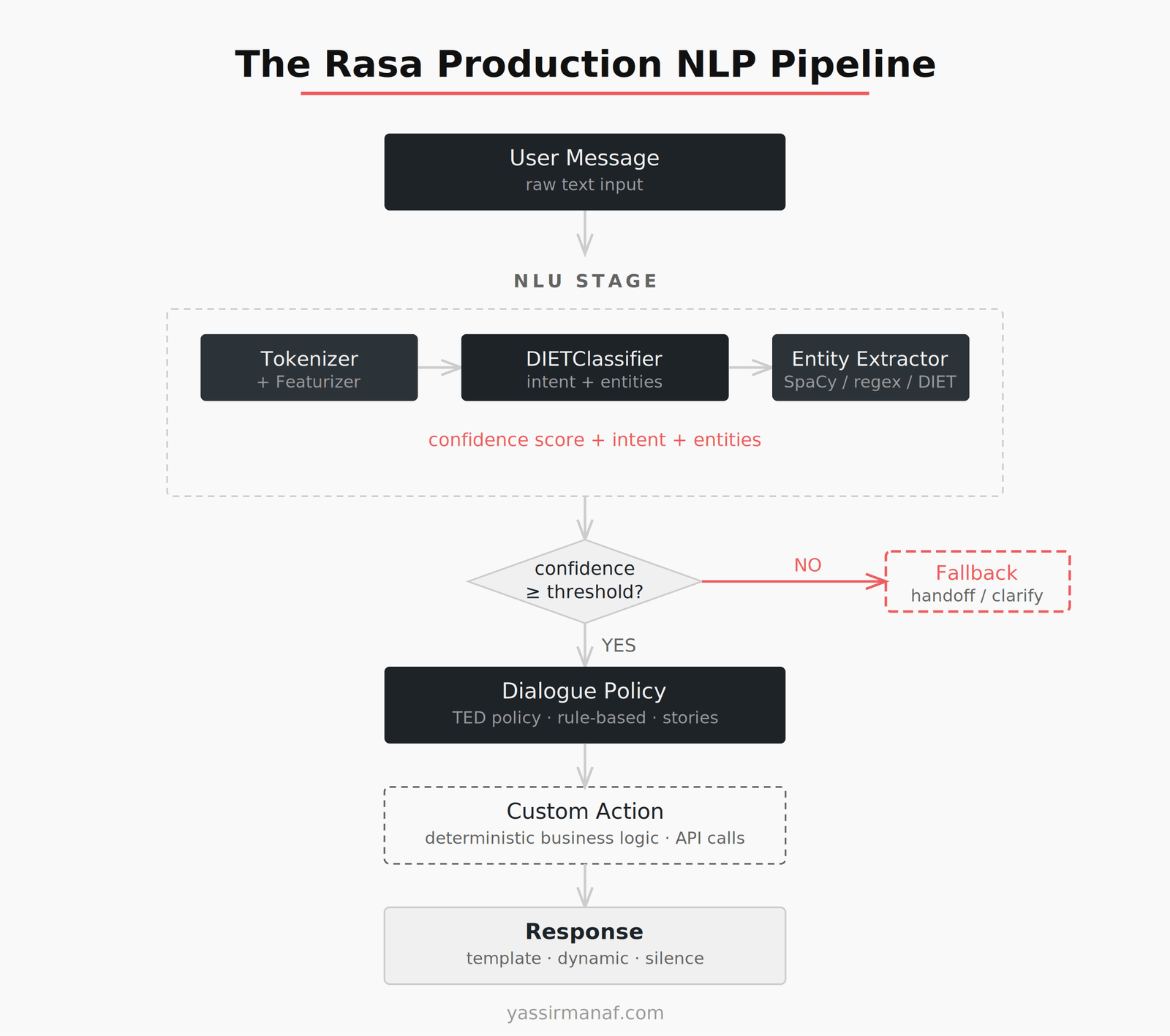
The Rasa pipeline, described simply: text comes in, passes through tokenization and featurization, the NLU model classifies intent and extracts entities, the dialogue policy decides what to do given current conversation state, and the assistant responds.
Simple to describe. Unforgiving in practice.
The NLU model — DIETClassifier by default — needs labeled training examples for every intent you define. The dialogue management layer needs stories or rules covering your conversation flows. There’s no generalization beyond what you’ve explicitly trained. The system only knows what you taught it, and it will tell you clearly when it doesn’t know something, via a confidence score below your fallback threshold.
That explicitness is the point. And it teaches you things that generative models hide.
Intent Design Is a Product Decision, Not a Data Science One
In every Rasa project I worked on, the single biggest predictor of production quality wasn’t model architecture or pipeline configuration. It was intent design.
How you carve up user intent determines everything downstream. Too coarse — one intent called “help” covering five different user needs — and your model can’t distinguish what a user actually wants. Too granular — separate intents for “cancel my order” and “I need to cancel” — and training data thins out and the model becomes fragile on anything phrased differently.
I ran a project with 47 intents at launch. Three weeks into production we merged 19 of them. Real user traffic proved those 19 were functionally indistinguishable — the same underlying need, expressed in too many overlapping ways to separate cleanly. The model accuracy had looked fine in testing. The intent taxonomy was wrong.
That redesign cost two weeks of relabeling and retraining. In an LLM-based system, you’d update a prompt. But in that LLM-based system, you might never notice the problem in the first place — the model would produce something for each input, and without explicit confidence scores and a fallback threshold, the failure is invisible. You get a plausible-sounding wrong answer instead of a visible low-confidence response.
Rasa makes the failure impossible to ignore. That’s uncomfortable. It’s also why Rasa-based systems often behave more predictably under edge cases than LLM-based equivalents.
Training Data Discipline: The 80% Nobody Talks About
Nobody who hasn’t done it understands how much of production NLP work is data work.
For a mid-size assistant — 30 to 50 intents, 15 to 20 entity types — you need hundreds of labeled utterances per intent. Minimum. The model needs variety: different phrasings, lengths, vocabulary registers. A training set with 10 utterances per intent will fail on anything outside those exact patterns.
On one project we had solid coverage for formal register — how we expected users to write — and almost nothing for informal input. Test metrics looked fine. Production metrics were poor. Users abbreviated, used slang, made typos, switched languages mid-sentence. We ran a second annotation pass targeting informal variants specifically. Three additional weeks. Unbudgeted.
The annotation work itself surfaces assumptions. You can’t label a sentence for intent without deciding what the sentence means, which forces you to decide what your system actually handles. That decision-making is product work dressed up as data work. Teams that treat it as a chore produce training data that encodes their blind spots.
This is exactly what LLMs solve, and I want to be honest about that. A modern frontier model handles informal input without a single training example. Significant, genuine advantage. But “handles” is doing work in that sentence. Handles how consistently? With what fallback behavior when uncertain? With what guarantees across similar inputs? Those questions don’t disappear with LLMs. They become harder to answer.
I covered some of this in What I Learned Deploying LLMs in Production — specifically where LLM variance shows up in systems that look fine on average but fail in the tail. The Rasa discipline of explicit training data is, in LLM terms, the discipline of building evaluation sets and running evals before you ship. The underlying engineering requirement doesn’t change. The form does.
Deterministic Dialogue Control and Why It Matters
The most underrated part of Rasa is dialogue management. Specifically: the ability to define conversation flows that behave identically every time, regardless of what the NLU model produces.
Rule-based dialogue in Rasa isn’t elegant. You write stories — example conversation paths — or rules that fire unconditionally given a condition. But it solves a class of production problem that probabilistic systems struggle with: hard business logic.
“If the user asks for a refund and their account has a fraud flag, stop the flow and escalate to a human agent.” That’s a rule. It should fire every time. Without exception. Not 97% of the time based on model confidence. Every time.
In Rasa, you write a custom action that checks the flag and a rule that triggers it. The behavior is guaranteed at the code level, not at the model level. There is no version of this logic that “usually works.”
In an LLM-based system, you either implement that logic outside the model — which is the right approach — or you instruct the model via prompt and trust it to comply. That trust is warranted most of the time. It is not absolute. In compliance-sensitive contexts — financial workflows, healthcare triage, anything a regulator might audit — the difference between “usually complies” and “guaranteed to execute” is not a product trade-off. It’s a legal one.
This is where the simplicity over engineering principle inverts itself. Using an LLM for hard business logic looks simpler. It is not. You’re hiding complexity inside a probabilistic system that was not designed to enforce invariants.
Entity Extraction: Where Inspectability Earns Its Weight
Entity extraction in Rasa is explicit: you define entity types, label them in training data, and configure extractors. SpaCy handles generic NER, regex extractors handle structured patterns, DIET handles context-dependent entities. Everything is declared.
The explicitness is tedious. It’s also where you catch the cases that matter.
One project involved extracting product codes from user messages. Codes followed a pattern: two letters, four digits, optional suffix. We built a regex extractor. Worked cleanly for standard input. Failed silently when users included spaces inside the code — which they did routinely, because the code appeared that way on their printed invoice.
We caught it because the failure was inspectable. Entity extraction produced no result, the fallback fired, we could write a test case, fix the regex, ship the fix in hours. Tight feedback loop.
In a system where an LLM handles extraction, the same failure looks like a confident wrong answer. Nothing downstream signals that the extraction was uncertain. You find out when something breaks further along the pipeline and trace it backwards.
Structured outputs and function calling have improved LLM inspectability. But the gap between “model usually returns the right structure” and “we can prove extraction behavior on this input class” is still real. Rasa closes that gap by construction.
What LLMs Actually Solve
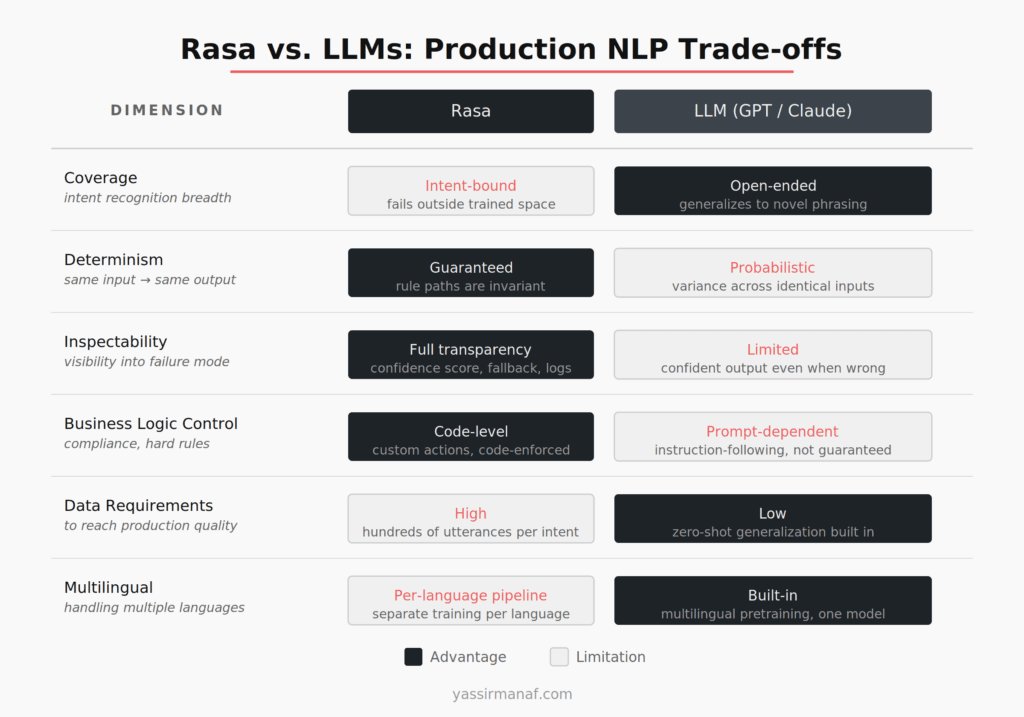
The Rasa constraints I’ve described are also Rasa’s biggest limitations. I want to name them clearly.
Coverage. Rasa-based systems are brittle outside the intent space they’ve been trained on. A user asks something you haven’t modeled — fallback, every time. Expanding coverage requires more annotation, more training, more iteration. Slow by design.
LLMs generalize. They handle paraphrase variation, ambiguity, and novel phrasing without training data. For the broad understanding layer, LLMs are strictly better. Not a close call.
Multilingual capability. A Rasa pipeline trained on French doesn’t handle Arabic. Different language, separate pipeline, separate annotation effort. An LLM with multilingual pretraining handles both with one model. For any multi-language product, that’s a significant operational simplification.
The question of when fine-tuning changes this calculus is worth reading through in Fine-Tuning vs. RAG: How I Decide. Even fine-tuned LLMs trade differently against Rasa’s explicit training, and the right choice depends on whether you need determinism or coverage more.
LLMs win on coverage, flexibility, and language generalization. Rasa still wins on determinism, inspectability, and auditable control flow. For many production systems you need both — the path is to use LLMs for understanding and keep deterministic logic outside the model boundary.
What the Old Constraints Transferred Into
Building Rasa production NLP taught me to think in terms of three distinct layers: understanding, state, and action. Those layers don’t disappear with LLMs. They get blurred in ways that create production debt.
Designing precise intents became designing precise prompts with structured outputs. Annotating training data became building eval sets and measuring before shipping. Writing dialogue rules became keeping business logic out of model inference — treating the model as a component in a system, not the system itself.
These aren’t automatic transfers. Engineers who go straight to LLMs without working through the Rasa-style constraints often rediscover these requirements the hard way — usually in production, usually under pressure, usually with stakeholders asking why the system behaved differently than it did in the demo.
The constraint-first approach isn’t faster. It’s not more enjoyable. But it builds the mental model that makes LLM-based systems more reliable, because you understand exactly what you’re giving up when you relax a constraint.
LLMs Didn’t Make the Discipline Optional
The disciplines that Rasa production NLP demands — precise intent design, training data rigor, deterministic control flow, inspectable failure modes — are still the disciplines that production NLP requires. LLMs changed where you apply them, not whether you need them.
Stop. That’s the sentence worth keeping.
The best LLM-based conversational systems I’ve seen are built by engineers who know what they’re giving up. They add evaluation. They separate business logic from model inference. They define failure modes and test against them. They are doing, with different tools, exactly what Rasa forced you to do through constraints.
You can skip that discipline. The system will work — until it fails in ways that are hard to locate and harder to explain to stakeholders. Rasa made failure visible from the first training run.
That visibility was the real product.
Built a production NLP pipeline with Rasa, or migrating one to LLMs now? I’d like to hear what the transition looked like. Find me on LinkedIn.
Leave a Reply