LLM output validation is not optional. Every production LLM system I’ve worked on has had at least one incident traced to an unvalidated model response that made it further downstream than it should have.
The model returned something plausible. The system accepted it. Something broke.
This is the failure mode nobody talks about enough: not hallucination in the abstract sense, but structurally or semantically invalid output that bypasses code that assumed the model always returns what you asked for. It doesn’t. Not always.
Why LLM Output Is Unreliable by Design
Models don’t optimize for correctness. They optimize for plausible continuation.
When you ask a model to return a JSON object with a status field set to one of three enum values, it doesn’t consult a schema — it predicts what text is most likely to follow your prompt. Most of the time that’s right. In production, “most of the time” is not good enough.
I’ve seen a model return a status value of "completed successfully" when the schema expected "complete". I’ve seen it omit a required field because the prompt context made the field seem implied. I’ve seen it wrap JSON in markdown code fences — \“json` — when the parser expected raw JSON.
None of these are model failures. They’re integration failures. The contract between your code and the model was never enforced.
What LLM Output Validation Actually Needs to Cover
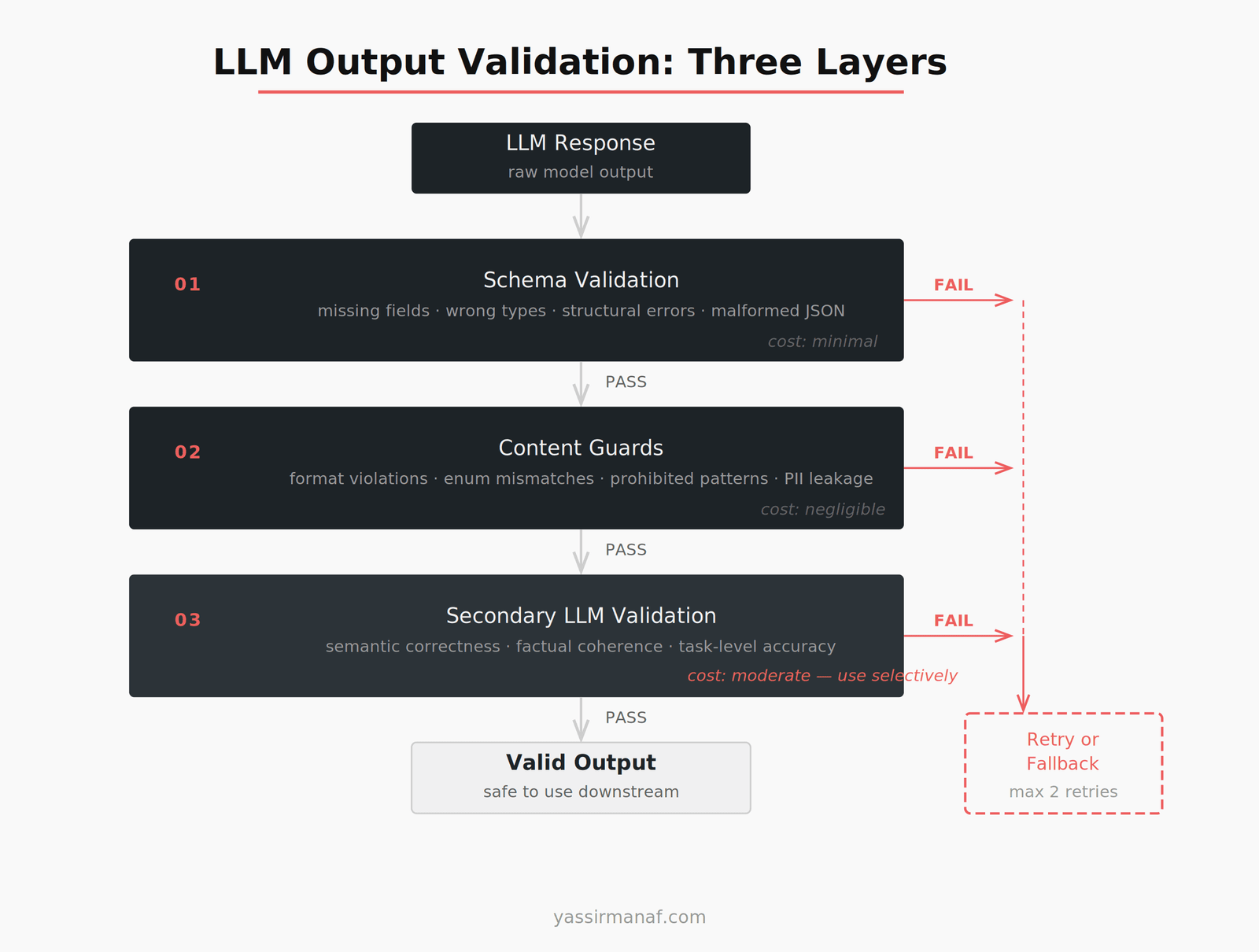
LLM output validation is not a single check. It’s a stack. Each layer catches a different class of failure, and each layer costs more than the previous one. You apply them in order and stop as soon as you catch a problem.
Layer 1 — Schema validation. Does the output match the expected structure? Layer 2 — Content guards. Are the field values semantically correct? Layer 3 — Secondary LLM check. Is the output correct in ways a schema can’t verify?
The key is applying them in this order. Schema validation is cheap — run it first. Secondary LLM calls are expensive — run them last, and only when the stakes justify it.
Schema Validation: Cheap, Fast, Non-Negotiable
Schema validation is the first gate. If the output doesn’t match the expected shape, nothing downstream should touch it.
For Python, Pydantic handles this well. Define your expected output as a model class, pass the raw LLM response into it, and catch the validation error before it becomes a downstream bug.
from pydantic import BaseModel, ValidationError
class AnalysisResult(BaseModel):
sentiment: str
confidence: float
summary: str
try:
result = AnalysisResult.model_validate_json(raw_output)
except ValidationError as e:
# trigger retry or fallback
OpenAI’s structured outputs, released in August 2024, help here. By passing a JSON schema directly into the API, the model is constrained at the token level to match the schema. Structural failures drop significantly.
But “significantly fewer” is not zero. Structured outputs don’t validate semantic correctness — a confidence field can return 0.0 when the model was clearly certain, and the schema won’t flag it. They also don’t protect you if your schema is wrong, and they only cover OpenAI models.
Schema validation is necessary. It is not sufficient.
Regex Guards for Content Constraints
Schema tells you the field exists and has the right type. Regex tells you the field value actually looks like what you expected.
This matters for format constraints — ISO dates, UUIDs, phone numbers — where a string field will pass schema validation whether it contains "2024-12-08" or "December 8th". It matters for enum values, where the model consistently returns semantically correct but syntactically wrong strings: "in progress" instead of "in_progress". It matters for prohibited patterns — PII that shouldn’t appear in output, or prompt fragments leaking into the response.
Content guards are cheap to run and catch a surprising share of production failures. In my experience, the most common output issues aren’t structural. The model returns the right content in the wrong format, reliably.
One principle I use: normalize before rejecting. Strip whitespace, lowercase string fields before comparing against enums, parse dates flexibly before failing them. The goal isn’t strict rejection — it’s correct behavior. If normalization recovers the output without a retry, that’s always cheaper than another API call.
Secondary LLM Validation Calls
Some failures can’t be caught by a schema or a regex. The field is present, the type is correct, the format matches — and the value is still wrong.
This is where a secondary LLM call earns its cost.
The pattern: take the original input, the model’s output, and a validation prompt, then ask a second call to verify the output is correct. The validation prompt is simpler than the original task: “Given this customer complaint, does this response correctly identify the issue? Return YES or NO with a brief reason.”
A few things I’ve learned running this in production:
Use a smaller model for the judge. Validation is a simpler task than generation. A smaller, cheaper model handles it fine. Running the same high-cost model to validate itself doubles your spend for marginal gain.
The judge prompt needs to be specific. A vague validation prompt produces vague validation. Be explicit about what correct looks like. Give examples of passing and failing output directly in the prompt.
Don’t use the same model for generation and validation. Same weights, same biases — it will agree with itself. Use a different provider, a different model family, or at minimum a system prompt that explicitly positions it as a critic.
Secondary validation adds latency and cost. Use it on outputs where correctness is load-bearing. Most outputs don’t need it.
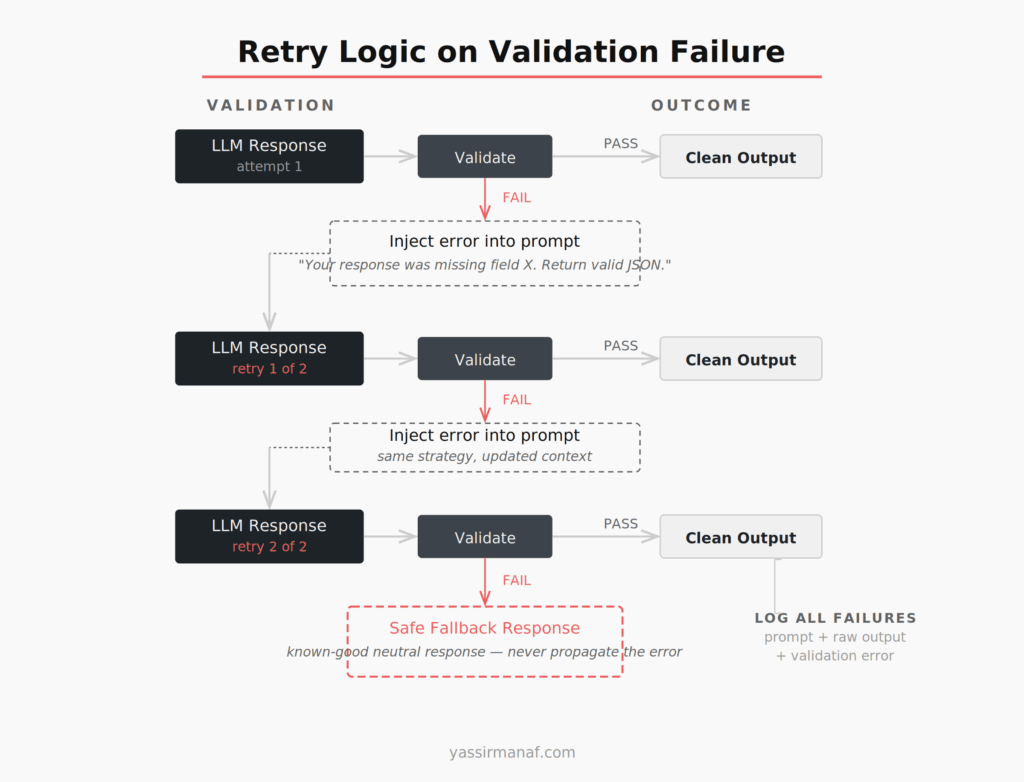
Retry Logic That Doesn’t Wreck Your Budget
When validation fails, you have three options: retry, fall back to a safe default, or surface an error.
Retry is the right first move. Most validation failures are transient — the model can produce valid output, it just didn’t this time. But retrying without discipline turns into runaway API spend. I’ve seen retry loops on expensive generation calls turn a $0.02 request into a $0.40 incident.
Here’s the structure I’ve settled on:
Max 2 retries. If the model fails validation twice in a row, a third attempt rarely fixes it. The problem is usually the prompt, not variance.
Feed the failure back. Don’t replay the same prompt. Tell the model what went wrong: “Your previous response was missing the required status field. Return only a valid JSON object matching this schema: [schema].” This materially improves retry success rate.
Fallback to a safe default — not an error. When retries are exhausted, return a known-good neutral response rather than propagating the exception. In most scenarios, “Unable to process this request” is better than a stack trace surfacing to the user or a downstream service receiving malformed data.
How Validation Failures Surface in Production
This is the part that’s missing from most write-ups. Not how to prevent failures — how to see them when they happen.
Every validation failure should be logged with full context: the original prompt, the raw model response, the validation error, and whether a retry succeeded. Without that, you’re debugging production incidents with no data.
Two metrics I track:
First-pass validation rate. What percentage of responses pass validation on the first attempt? If this drops below 90%, something changed — the model, the prompt, or the input distribution. Any of those is worth investigating.
Retry success rate. Of the responses that failed first-pass, what percentage passed on retry? A low retry success rate means the problem is structural — the prompt isn’t giving the model enough to produce valid output consistently.
Both are cheap to emit and expensive to be without. Wire them into whatever observability stack you’re running.
One failure mode worth naming: silent corruption. The output passes schema validation, the content looks plausible, and the value is still wrong in a way your system accepts without complaint. The job description generates, looks fine, ships — and only a human reading it notices the requirements are for a different role entirely.
There’s no automated check that catches everything. The honest position is: invest in validation proportional to the cost of failure. High-stakes outputs need stricter checks. Low-stakes outputs don’t need a secondary LLM call.
The Cost Equation
Validation adds cost. Retries add cost. Secondary calls add cost.
A well-designed validation stack adds roughly 10–20% to per-request LLM spend in my experience. Not free. But predictable — and far cheaper than unvalidated failures making it to production.
The math that matters is not “what does validation cost?” It’s “what does a validation failure cost downstream?” For a chatbot response that reads slightly off, the cost is low. For an automated workflow that writes to an external system based on model output, the cost can be irreversible.
Calibrate your stack to the failure cost. Not to some abstract ideal of correctness.
Where cost actually blows up: retrying expensive generation calls. If you’re generating a 2,000-token output and validation fails, retrying is significant spend. The fix is to validate earlier — run a schema check on an intermediate structured step before triggering the expensive generation. Catch failures when they’re cheap to catch. This is the same instinct I apply in every system I build, and it shows up in how I approach simplicity over engineering at every layer — validate cheap, generate expensive.
The same cost logic applies to fine-tuning decisions. If you’ve fine-tuned a model to produce structured output, you still need validation — fine-tuning improves consistency, it doesn’t guarantee it. I wrote more about where fine-tuning fits versus retrieval-based approaches in fine-tuning vs RAG, but the validation requirement doesn’t go away with either approach.
What I Actually Use in Production
Not a library survey. Here’s the stack:
Pydantic for schema validation — every LLM response that needs to be parsed goes through a model class, no exceptions.
Prompt-level output constraints — I specify the format with a concrete example in the prompt, not just a description. The model matches an example more reliably than it follows a textual specification.
Normalization before rejection — whitespace stripping, case normalization, common synonym mapping for enum fields. Recover what you can before triggering a retry.
One retry with error feedback — single retry, error injected into the prompt. If it fails again, fallback. I’ve never needed more than two total attempts for a well-prompted task.
Secondary LLM call only on high-stakes outputs — outputs that feed automated workflows, external writes, or user-facing content that can’t be reviewed before shipping. Everything else doesn’t justify the cost.
The trap is building elaborate validation infrastructure before you know where failures actually occur. Start with schema validation and a single retry. Instrument it. Add complexity where the data tells you to. That principle is consistent with everything I’ve described in getting LLMs into production — measure the failure mode before you engineer against it.
Running into unexpected validation failure patterns in your LLM system? I’d like to hear what you’re seeing. Find me on LinkedIn.
Leave a Reply