A repeatable prompt engineering process is the difference between an LLM feature you can maintain and one that quietly breaks every time the model updates.
Most teams treat prompt writing as a creative act. Someone on the team has “good instincts,” they iterate by feel, and when the output looks right, it ships. That works fine in a notebook. It fails in production — because intuition doesn’t transfer, doesn’t version, and doesn’t catch regressions at two in the morning.
I’ve been integrating language models into production systems since 2017, starting with Rasa-based conversational AI long before GPT-4 existed. The tooling has changed dramatically. The engineering discipline required to make these systems reliable has not. What works for a Rasa NLU pipeline also works for a GPT-4 prompt: define your inputs and outputs clearly, test every change, and track what you changed and why.
The teams getting consistent results from LLMs aren’t the ones with the most creative prompt writers. They’re the ones who run the prompt engineering process the way they run code reviews: with evaluation criteria, version history, and automated regression tests.
Why the “Skill” Framing Breaks Down in Production
The “skill” framing implies prompts flow from talent. You find someone with good instincts, they write clever prompts, and the model cooperates. That holds up in demos.
It falls apart in production because intuition doesn’t transfer. When the model updates, when requirements change, when the person leaves — you’re left with prompts nobody understands and no way to safely evolve them.
Early in one GPT-4 integration project, a senior developer became the de facto prompt person. He had strong instincts and the outputs were genuinely good. When he rotated off the project six weeks later, the prompts went with him — undocumented, untested, living in a Notion doc with no explanation of why any instruction was phrased the way it was.
When production behavior changed, nobody could trace it. Nobody knew what was safe to modify.
I’ve inherited three LLM integrations in this state. Each had the same problem: prompts with no tests, no documented intent, no baseline to compare against. Changing anything felt like defusing a device with no diagram. So nothing changed, and each system slowly drifted out of alignment with what the product actually needed.
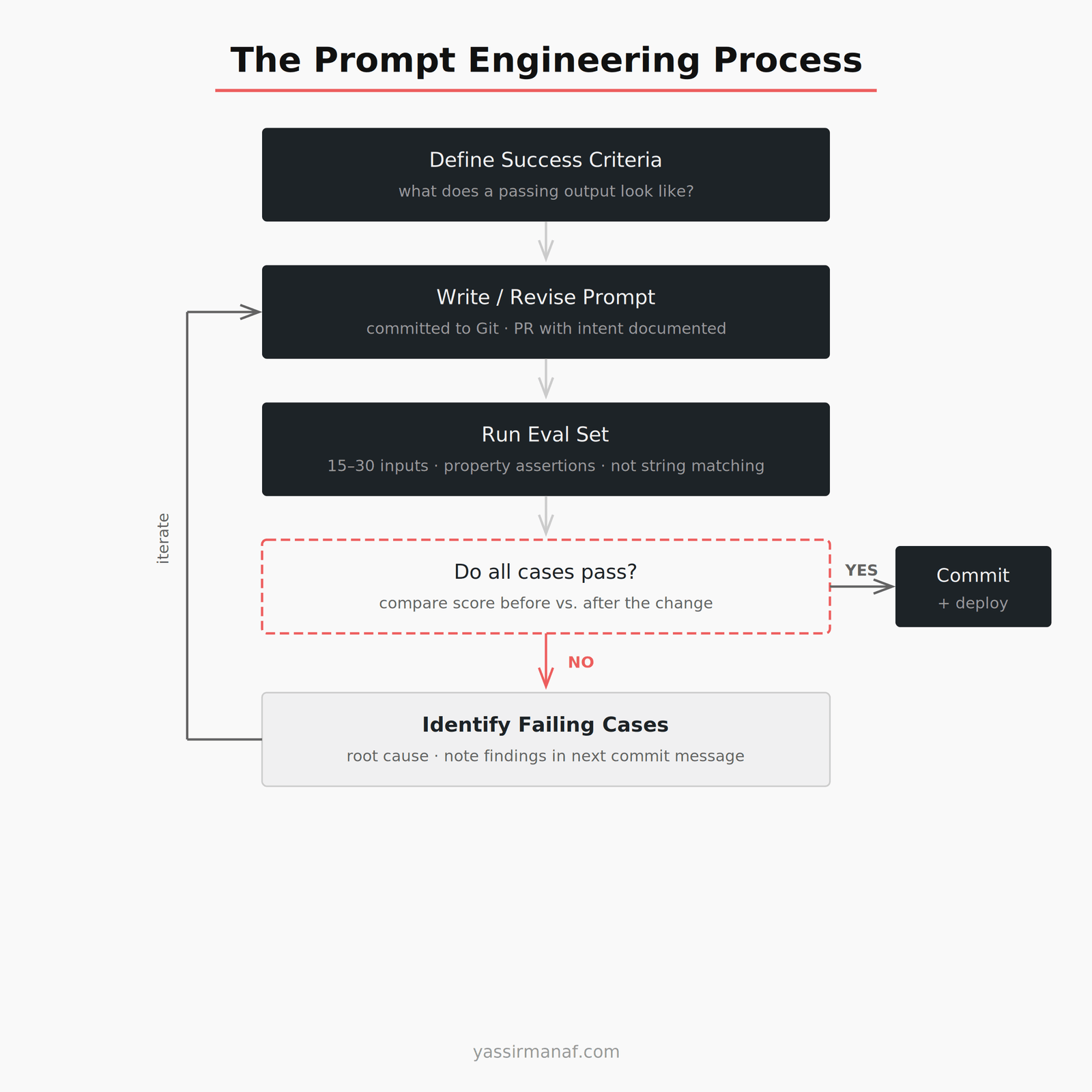
Start the Prompt Engineering Process Before You Write a Single Token
The common mistake is writing the prompt first. It isn’t.
Before touching the system prompt, define what passing looks like. What should the output always contain? What should it never contain? What format is required? How long should it be?
For a summarization feature I built on GPT-4, we defined three criteria before writing a single instruction: output must be under 80 words, it must not introduce information absent from the source, and it must preserve the sentiment of the original text. Those three criteria became the eval set. Every prompt iteration was scored against them.
Without that definition, iteration is guessing. You change a word, the output feels better, you ship it. Then a user reports hallucinated company names. You never caught it because “feels better” was not a test.
Define success before you write. That definition is the eval set.
Version Control Your Prompts
Prompts are code. They’re instructions executed inside an interpreter — the model — and they produce outputs. Treat them accordingly.
Every prompt I ship lives in version control. Not a shared Notion doc, not a Google Doc with “v3_FINAL_USE_THIS” in the title. A Git repository with commit messages explaining why the change was made, not just what changed.
“Tightened format constraint” is useless in three months. “Tightened format constraint after observing the model adding an unsolicited preamble sentence on approximately 8% of calls in staging — confirmed across 15 test inputs” gives you something to act on.
The PR template I use for every prompt change is four items:
- What behavior triggered the change
- What the previous output looked like (include a real example)
- What the new output looks like
- Which eval cases were affected and how scores shifted
That’s ten minutes of documentation per change. It’s also the difference between a system you can hand off and one you have to rewrite.
The review process serves a second purpose: it forces you to explain your reasoning before you see the results. If you can’t write a PR description for a change, that’s usually a signal the change is exploratory. Exploratory changes belong in a development branch. They don’t reach production until the eval set confirms they work.
Every prompt change goes through a PR. No exceptions. You need the history.
Build a Small, Stable Eval Set
An eval set is a collection of inputs paired with expected output properties. For classification tasks, the expected output is a label. For generation tasks, it’s a rubric: does the output meet these specific criteria?
Keep it small on purpose. Fifteen to thirty examples is enough to catch regressions. A larger eval set creates friction — engineers skip running it because it takes too long. A small set you actually run beats a thorough one that collects dust.
For the summarization feature: 20 source texts, each with a hand-labeled checklist against the three criteria. Every prompt change is scored against all 20. Score before, score after. If the score drops, the change doesn’t ship.
The eval set also functions as documentation. A new engineer joining the project reads the eval cases and immediately understands what the prompt is producing — without reading the prompt itself. More useful than any inline comment.
The eval cases should cover three categories: typical inputs the prompt handles well, edge cases that previously caused failures, and inputs where the data itself might confuse the model. You don’t need many from each category. You just need them to exist.
Run Regression Tests on Every Prompt Change
Model behavior is non-deterministic. The same input through GPT-4 produces similar but not identical outputs across calls. This makes regression testing feel harder than it is. The fix: test properties, not exact strings.
Don’t assert that the model returns a specific sentence. Assert that the output is under 100 words, contains no HTML tags, starts with a capital letter, and doesn’t include the phrase “As an AI language model.” Those property checks are stable across runs. Exact string matching is not.
For structured outputs — classification labels, yes/no decisions, specific JSON fields — exact matching is appropriate. If your prompt is specific enough, the model should reliably return "sentiment": "negative". Variability there is a prompt problem, not a testing limitation.
The script isn’t complicated. Load the prompt from a text file in the repo. For each input in the eval set, call the API with the system prompt and user content. Check the response against your property assertions. Write the results to a log. If any assertion fails, exit with a non-zero status. That’s it. No framework required to start.
The OpenAI Evals framework provides more structure for teams that need it at scale.
I run these checks in CI on every prompt change. The whole pipeline takes about 30 seconds on 20 inputs. That 30 seconds has blocked bad changes more times than I can count.
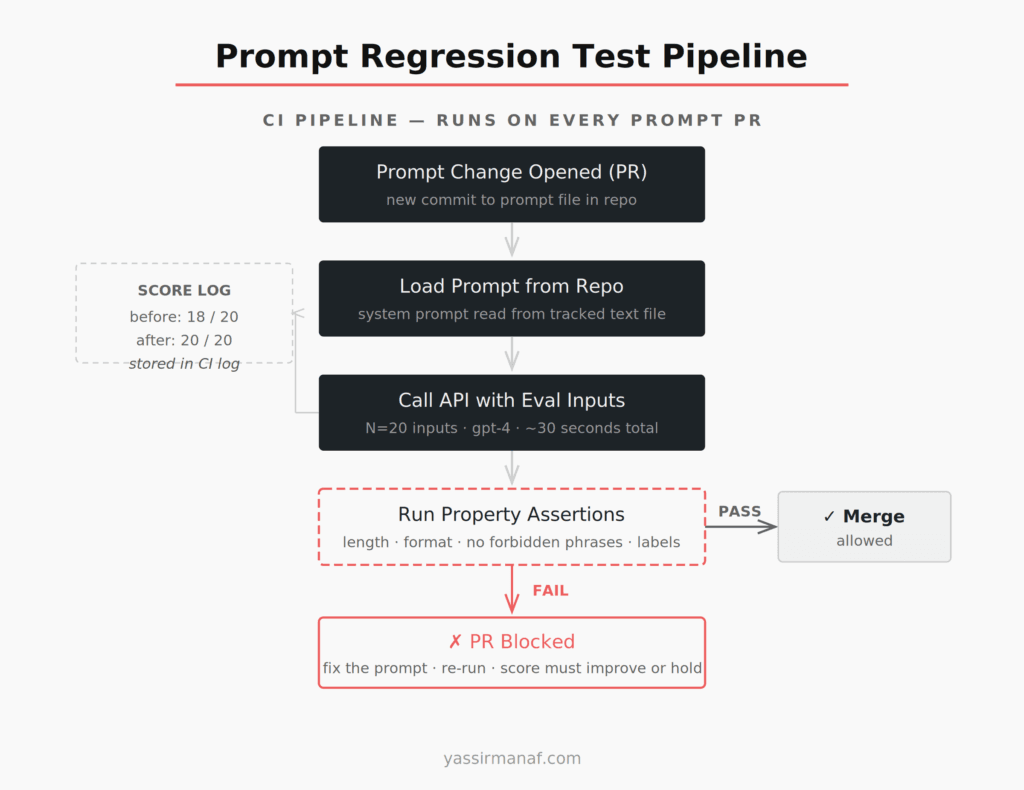
The Prompt Engineering Process in a Real Workflow
Here’s what this looks like day-to-day on a real project.
A requirement comes in: the summarization output needs to include a one-sentence “key action” at the end. You update the prompt. You run the eval set. Core criteria pass, but one of the 20 inputs produces a 94-word output — just over the limit. You tighten the word count instruction. Re-run. All 20 pass.
PR description: “Added key action requirement. Eval scores before: 19/20. After: 20/20. One failure in first draft on a long-form input — resolved by adding an explicit word count instruction.” Merged in 25 minutes. Deployed.
The improvement didn’t come from inspiration. It came from measurement.
That’s the whole thing.
Separate the Instruction from the Runtime Data
One thing I see skipped constantly: keeping the static and dynamic parts of a prompt cleanly separated.
A system prompt has two layers. The static layer is the instruction — the behavior you’re engineering. The dynamic layer is runtime context: user input, retrieved content, dates, anything that changes per call. These should never be tangled together in the same string.
A prompt that concatenates the system instruction and user content into a single string is harder to version than one where the system message is a clean constant and the user message is injected from the application. The former means your eval inputs are testing the concatenation logic alongside the instruction. The latter means your evals test only the thing you’re actually trying to engineer.
Keep them separate. The system prompt lives in version control and goes through the eval process. The runtime values are injected at call time by the application. The boundary between them should be explicit and consistent across every call.
This discipline also simplifies your eval set. You’re testing the instruction against varied data — which is what you actually want to verify.
What Happens When the Model Updates
OpenAI updates GPT-4 without notice. The model you built against in March is not the same model running in July.
With eval sets and version-controlled prompts, a model update is a manageable event. You re-run your evals against the new model, check your scores, see what changed. You have a baseline. You know what broke and where to focus.
Without those things, a model update is a mystery. Production behavior shifts and you spend days figuring out whether it’s the model, the prompt, the data, or some combination of all three.
The prompt engineering process doesn’t prevent model drift. It makes drift visible.
For the broader architecture of building reliable systems on top of LLMs — how to isolate the model layer, what to monitor, where things fail at scale — my earlier post on LLM in production covers the structural decisions I’d make before thinking about prompt management.
The Discipline, Not the Talent
None of this is new engineering. Version control, eval sets, property-based assertions, CI pipelines — these are tools every engineer already knows. The only new part is applying them to prompts.
The reason teams skip it is the same reason teams skip tests in general. It feels slower upfront. It’s faster to tweak a prompt and deploy it than to update an eval case and run a pipeline.
Until it isn’t.
Every hour I’ve put into eval infrastructure has returned in debugging time I didn’t spend. The prompt engineering process isn’t overhead. It’s just the work.
Prompts deserve the same rigor as the code around them. If you’re shipping prompts without version history and assertions, you’re not doing prompt engineering.
You’re doing prompt hoping.
What does your prompt testing setup look like? Find me on LinkedIn.
Leave a Reply