The first time a tenant’s prompt leaked into another tenant’s context window, I didn’t find out from monitoring. I found out from a customer support ticket. A user saw a competitor’s product names in their LLM-generated summary. That’s the kind of failure that ends contracts.
Multi-tenant LLM architecture is a fundamentally different problem than multi-tenant web apps. In a traditional SaaS, tenant isolation means separate databases or row-level security. In an LLM system, isolation means preventing one tenant’s data from contaminating another tenant’s prompts, responses, retrieval results, and cost attribution — all while sharing the same expensive GPU infrastructure.
I run a platform that serves LLM features to multiple tenants from shared infrastructure. Here are the isolation patterns I’ve implemented, which ones held up, and where I had to abandon shared approaches entirely.
Why traditional multi-tenancy breaks with LLMs
Standard multi-tenant patterns assume stateless request handling. A web API receives a request, queries the right database, returns a response. Tenant isolation lives in the data layer.
LLM systems break this model in three ways.
First, the context window is state. Every token in a prompt is active state that the model reasons over. If tenant A’s document appears in tenant B’s retrieval results, the model doesn’t know it’s a contamination. It treats it as context and uses it. There’s no access control inside a context window.
Second, LLM responses are non-deterministic. The same prompt can produce different outputs, which means you can’t reproduce a contamination incident after the fact unless you log the full prompt. Most teams don’t log full prompts because they contain sensitive tenant data. This creates a debugging paradox I’ll come back to.
Third, cost attribution is approximate. A single API call costs money per token, but tenants share the same model endpoint. Tracking cost per tenant requires counting tokens per request and mapping them back — straightforward in theory, surprisingly messy with retries, streaming responses, and cached completions. I wrote about the broader cost challenge in Azure Costs in AI Workloads: Where the Money Actually Goes.
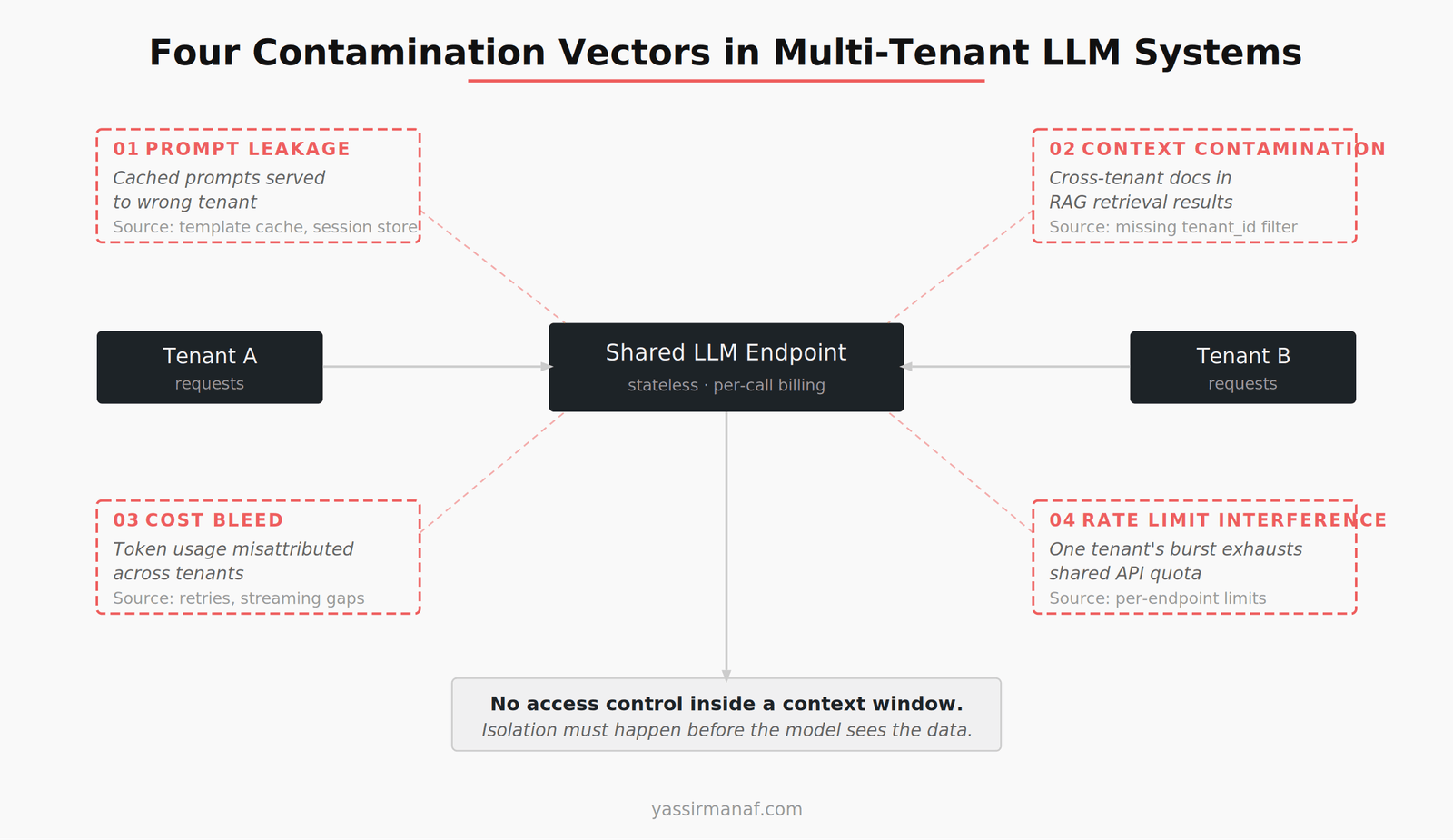
The four contamination vectors I design against
I categorize multi-tenant LLM architecture risks into four vectors. Every design decision maps back to one of these.
Prompt leakage. Tenant A’s system prompt or few-shot examples appearing in tenant B’s request. This happens when you share prompt templates across tenants and a caching layer serves the wrong cached prompt. It also happens when conversation history is stored in a shared session store without strict tenant partitioning.
Context contamination. Tenant A’s documents appearing in tenant B’s RAG retrieval results. This is the most common failure mode I’ve seen, and the hardest to detect without explicit testing. A misconfigured metadata filter on a vector search query returns documents from the wrong tenant. The model happily uses them. Nobody notices until a human reads the output and sees unfamiliar content.
Cost bleed. Tenant A’s usage being attributed to tenant B, or unattributed entirely. This isn’t a security issue — it’s a business issue. If you can’t attribute costs per tenant with at least 95% accuracy, your pricing model is a guess. I was off by 18% on per-tenant cost attribution in my first implementation because I wasn’t accounting for retry tokens.
Rate limit interference. Tenant A’s burst traffic exhausting shared rate limits and degrading tenant B’s experience. This one is obvious in theory but tricky in practice because most LLM API rate limits are per-endpoint, not per-tenant. You have to build tenant-level throttling yourself.
Data isolation for RAG: separate indexes vs. filtered shared index
This is the decision that generates the most debate, and I’ve tried both approaches in production.
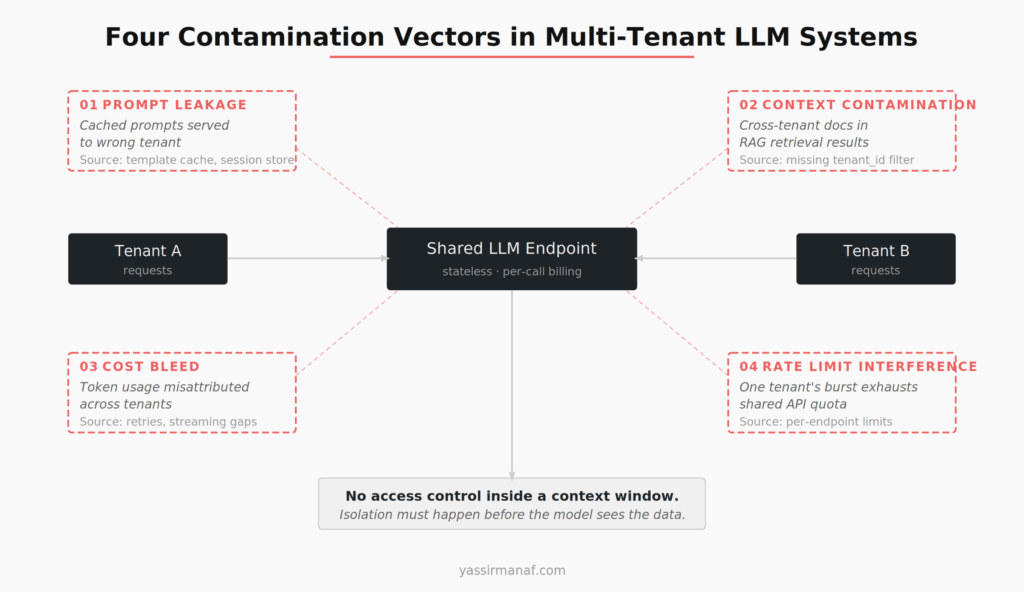
Separate vector indexes per tenant means each tenant gets their own collection in your vector database. Complete isolation by default. No chance of cross-tenant retrieval. Simple to reason about.
The cost: you multiply your infrastructure. Ten tenants means ten indexes, each consuming memory and storage independently. Vector databases don’t share well — each index maintains its own HNSW graph or IVF structure. I went from a single 8GB index to ten indexes averaging 3GB each, tripling my vector database costs. Index management becomes a provisioning problem: onboarding a new tenant means spinning up a new collection, configuring its embedding pipeline, and monitoring its health independently.
Filtered shared index means all tenants share one index, with a mandatory tenant_id metadata field on every vector. Every query includes a metadata filter: WHERE tenant_id = 'xyz'. One index, one infrastructure cost, simpler operations.
The risk: a missing or misconfigured filter query returns cross-tenant results. This is exactly how my first contamination incident happened. A code path that built the retrieval query didn’t include the tenant filter during a specific edge case — when the user’s query was empty and the system fell back to a “recent documents” lookup. That fallback path had been added by a different developer who didn’t know about the tenant filter requirement.
I wrote about vector database operational patterns in Vector Database Production: Lessons From Scaling to 10M Embeddings. The tenant isolation question adds another layer on top of those fundamentals.
What I actually use: separate indexes for tenants with compliance requirements or high data sensitivity, filtered shared index for everything else — with a critical safeguard. Every retrieval query passes through a tenant isolation middleware that injects the filter. No application code touches the vector database directly. The middleware is the only code path that builds queries, and it refuses to execute any query without a tenant_id filter.
That middleware eliminated the class of bugs where a developer forgets the filter. It moved tenant isolation from “every developer must remember” to “the system enforces it by default.” Before the middleware, we had two contamination incidents in three months. After: zero in six months.
Per-tenant cost attribution that actually adds up
Every LLM API call has a token cost. In a multi-tenant system, you need to know which tenant generated which tokens.
My approach: wrap every LLM call in a metering layer that captures the tenant ID, request tokens, response tokens, model used, and whether the call was a retry. This runs before the response reaches the application. Every call gets a cost record in a time-series table.
The part I got wrong initially: retries. When an API call fails with a rate limit error and the system retries, the retry tokens are real costs. My first implementation only metered successful responses. I was systematically underreporting costs for tenants with high error rates — and those were exactly the tenants generating the most expensive traffic.
The other trap: streaming responses. When you stream an LLM response token by token, you don’t know the total response length until the stream completes. If the stream fails midway, you’ve consumed tokens that don’t appear in a final response object. I meter tokens as the stream progresses now, not after completion.
Concrete numbers from my system: after fixing retry and streaming metering, my per-tenant cost attribution accuracy went from 82% to 97%. The remaining 3% gap comes from shared infrastructure costs (the vector database, embedding generation, logging) that I allocate proportionally by query volume rather than attributing precisely.
Tenant-aware rate limiting
Most LLM providers give you a single rate limit per API key. If you serve ten tenants through one key, a single tenant can exhaust your entire quota.
I implement a two-layer rate limiting approach. The outer layer is a token bucket per tenant, enforced before the request reaches the LLM provider. Each tenant gets a configurable tokens-per-minute and requests-per-minute allocation. The inner layer is the provider’s own rate limit, which acts as a hard ceiling for the entire system.
The tenant-level buckets are sized based on their pricing tier, not equal allocation. A tenant paying for a higher tier gets a larger bucket. When a tenant exceeds their bucket, they get a 429 response with a Retry-After header — the same pattern they’d see from the LLM provider directly, which makes client-side handling straightforward.
The complication: burst traffic. Some tenants have legitimate usage spikes — batch processing, end-of-month reporting. A rigid per-minute limit penalizes these patterns. I added a burst allowance: tenants can exceed their rate by up to 3x for 30 seconds, borrowing against their next minute’s allocation.
Before tenant-level rate limiting, one tenant’s batch job consumed 70% of our API quota for 45 minutes. Three other tenants hit timeouts. After implementing per-tenant buckets, the same batch job gets throttled gracefully and other tenants maintain baseline performance.
Tenant-aware logging without logging tenant data
Here’s the debugging paradox I mentioned earlier. To diagnose multi-tenant LLM issues, you need to see the full prompt — system instructions, retrieved documents, user input, model response. But full prompts contain tenant data that may be confidential, regulated, or both.
My logging strategy uses three tiers.
Tier 1: metadata only. Every request logs tenant ID, model, token counts, latency, status code, and a request hash. No prompt content. This handles 90% of debugging: latency issues, error rates, cost anomalies.
Tier 2: redacted prompts. For deeper debugging, I log prompts with PII and tenant-specific content replaced by placeholders. A redaction pipeline strips entity names, numbers, and document content, replacing them with typed tokens like [COMPANY_NAME] or [DOCUMENT_CONTENT_3]. This lets me see the prompt structure and flow without seeing tenant data. Enough to diagnose template errors, retrieval count issues, and system prompt problems.
Tier 3: full prompts in a secure, access-controlled store. Only available for tenants that explicitly opt in, stored encrypted, with access limited to incident response. Retention: 72 hours. This is the last resort for reproducing contamination incidents. Most tenants don’t opt in, and I’ve only needed it twice.
The three-tier approach replaced an earlier system where we logged everything and relied on access controls to protect it. That approach was technically compliant but practically risky — one misconfigured IAM role away from exposing tenant data in a log search. Reducing what gets logged is more robust than controlling who can read it.
Where shared infrastructure works and where it breaks
After running multi-tenant LLM systems for over a year, here’s where I’ve landed on shared vs. dedicated resources.
Share the model endpoint. LLM API calls are stateless from the provider’s perspective. There’s no cross-tenant contamination risk at the model layer — the model doesn’t remember previous requests. Share the endpoint, meter per tenant, rate limit per tenant.
Share the embedding pipeline. Embedding generation is a pure function: text in, vector out. No tenant state. Share it, and batch embedding requests across tenants for efficiency. I reduced embedding costs by 35% by batching cross-tenant embedding jobs into single API calls with post-processing that routes results back to the right tenant.
Don’t share conversation history storage. This is where I got burned. I initially stored all tenant conversation histories in a shared Redis instance with tenant-prefixed keys. A key collision during a migration — two tenants with overlapping session IDs — caused one tenant to see another’s conversation. Separate Redis instances per tenant now. The infrastructure cost increase was minimal compared to the risk.
Don’t share prompt template management. Tenants customize their system prompts, few-shot examples, and output formatting. I store these in a per-tenant configuration store. A shared template engine with tenant overrides sounds elegant until a default template update overwrites a tenant’s custom configuration. Happened once. Never again.
Conditionally share the vector database. For most tenants, a shared index with the tenant isolation middleware is sufficient. For tenants with regulatory requirements or extremely sensitive data, separate indexes are non-negotiable. The tenant’s compliance profile drives this decision, not my architectural preference.
The checklist I run before onboarding a new tenant
Every new tenant goes through an isolation verification before their data enters the system.
I run a synthetic contamination test: inject test documents for the new tenant, then execute retrieval queries from every existing tenant’s context. If any existing tenant’s query returns the new tenant’s documents, the isolation is broken. This catches filter misconfigurations, index routing errors, and middleware bugs before real data is at risk.
I verify cost metering by sending 100 test requests through the new tenant’s pipeline and reconciling the metered token count against the LLM provider’s usage dashboard. If the numbers diverge by more than 2%, something is wrong with the metering layer.
I confirm rate limit isolation by running a burst test for the new tenant and monitoring whether any existing tenant’s latency degrades.
These tests take about 20 minutes to run. I’ve caught configuration issues on three out of the last ten tenant onboardings. Every single one would have been a production incident if the tenant had gone live without the check.
Multi-tenant LLM architecture is an isolation problem, not a scaling problem
Most architecture discussions about multi-tenancy focus on scaling: how to serve more tenants efficiently. In LLM systems, the primary challenge isn’t scale. It’s preventing tenants from affecting each other in ways that are difficult to detect and expensive to fix.
The patterns that work share a common principle: enforce isolation at the infrastructure layer, not the application layer. Developers forget filters. Template engines have bugs. Session stores collide. The systems that prevent contamination are the ones where isolation is a structural guarantee, not a convention that every code path must follow.
I’m still iterating. The cost attribution gap between 97% and 100% bugs me. The three-tier logging could be more automated. Tenant-level rate limiting doesn’t handle multi-model tenants cleanly yet.
But the core approach — treat every shared resource as a contamination risk, enforce isolation through middleware and infrastructure rather than developer discipline, test isolation before every tenant goes live — has held up. Zero contamination incidents in the last eight months.
That’s what I optimize for. Not elegance. Isolation.
Running multi-tenant AI systems? I’d like to hear what isolation patterns you’ve landed on. Find me on LinkedIn.
Leave a Reply