LLM context window production decisions are the most underengineered part of most AI systems. The context window is not a feature to maximize. It’s a budget to manage. Every token you send costs money, adds latency, and past a threshold, actively degrades the quality of what you get back.
I learned this the expensive way. On a conversational AI system processing thousands of customer interactions daily, I watched our Azure bill climb 4x in three months because we treated the context window like a dumpster: throw everything in, let the model sort it out. The model did not sort it out. Response quality dropped. Costs spiked. Latency made the product feel broken.
This article is about what I learned managing context windows in production — not the theory of attention mechanisms or model architecture, but the engineering decisions that actually control cost, latency, and accuracy in real systems.
What the LLM context window actually means in production
Model providers advertise context window sizes like car manufacturers advertise horsepower. GPT-4 Turbo offers 128K tokens. Claude supports 200K. The implication is clear: bigger is better, and you should use all of it.
In production, the context window is an upper bound on how much text you can send per request. That’s it. It says nothing about how well the model will use that text, how much it will cost, or whether stuffing it full will improve your results.
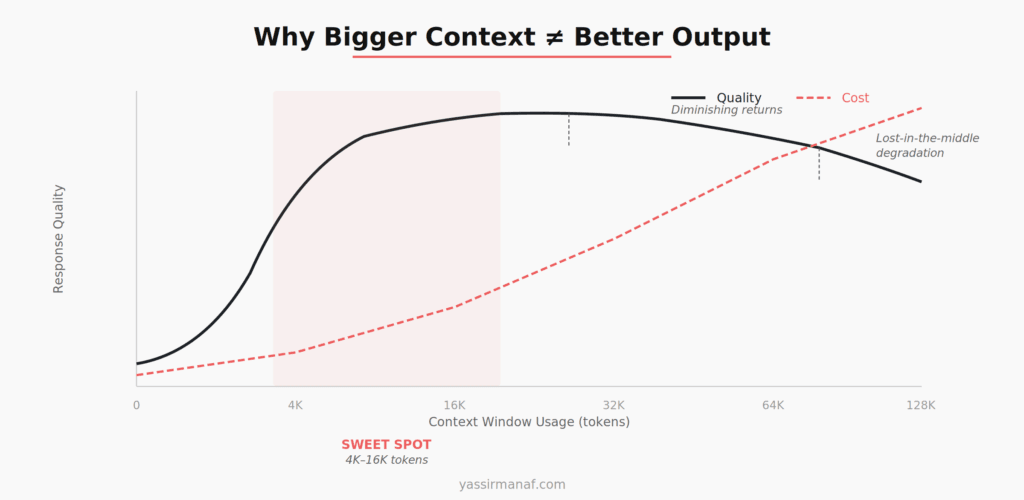
Here’s what matters more than the number on the spec sheet: input tokens are billed per request, latency scales roughly linearly with input size, and model attention is not uniform across the entire window. Research on the “lost in the middle” phenomenon has shown that LLMs attend strongly to the beginning and end of their context while struggling with information buried in the middle. This isn’t a bug that will get patched. It’s a fundamental property of how transformer attention works at scale.
So when you fill a 128K context window with 95K tokens of history and retrieved documents, you’re paying for all of it, waiting for all of it, and the model is effectively ignoring a significant chunk of what’s in the middle.
That changes the engineering calculus entirely.

Context stuffing: the default mistake
The first approach every team tries — including mine — is context stuffing. You have a large context window, so you use it. Send the full conversation history. Retrieve every potentially relevant document from your vector store. Include all the metadata. Let the model figure out what’s important.
This felt responsible. More context means better answers, right?
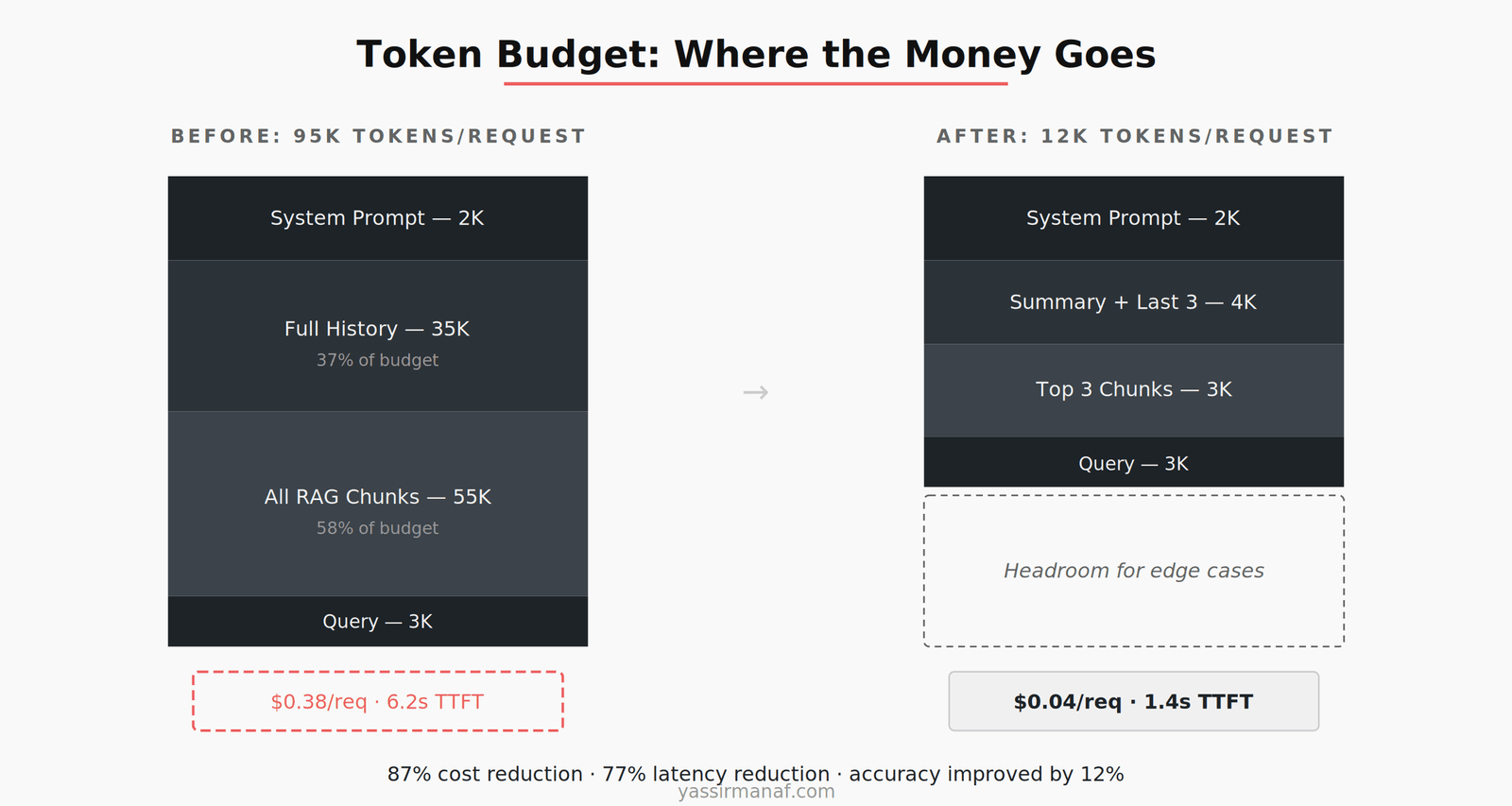
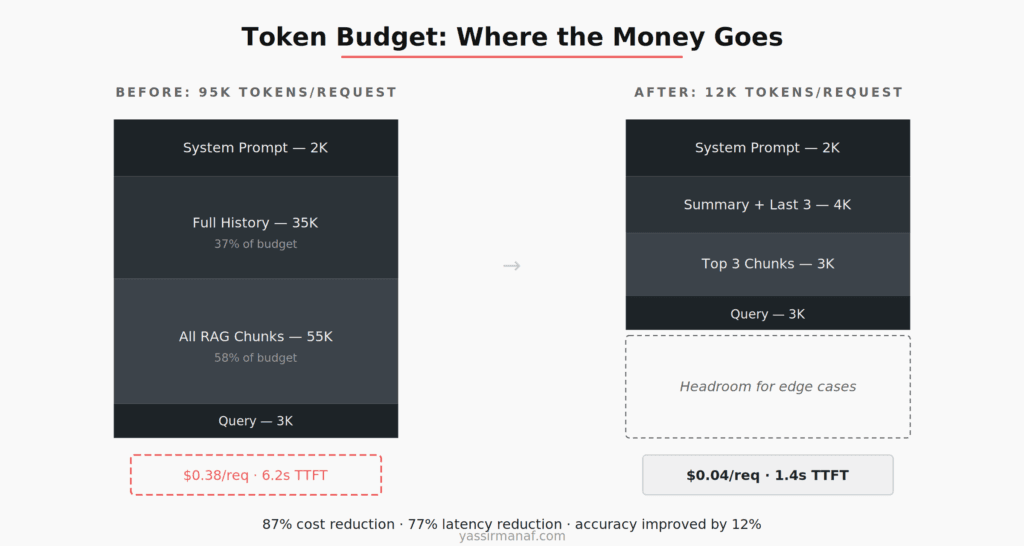
Wrong. On our system, I ran a controlled comparison over two weeks. Requests using 80-95K tokens versus requests using 8-12K tokens of carefully selected context. The results were unambiguous.
The large-context requests cost $0.38 per interaction on average. The selective ones cost $0.04. Time to first token went from 6.2 seconds to 1.4 seconds. But the number that surprised me most: accuracy on our internal evaluation set was 12% higher with less context. The model was more accurate when we gave it less to work with — because what we gave it was relevant.
The failure mode of context stuffing isn’t that the model crashes or throws an error. It’s subtle. The model produces plausible-sounding responses that miss the actual point because the relevant information was buried under 60K tokens of tangentially related content. You don’t notice until you measure. This is the core LLM context window production challenge: the failure is silent. I’ve written about the broader pattern of running LLMs in production — context management is one of the decisions that separates a working demo from a reliable system.
Retrieval over stuffing — every time
The alternative to stuffing is retrieval. Instead of sending everything, you send only what the current query actually needs. This is the core insight behind RAG architectures, but it applies equally to conversation history, system prompts, and any other content competing for space in your context window.
I budget my context window the way I budget cloud resources: with hard limits per category.
For a typical production request on our system, the allocation looks like this: 2K tokens for the system prompt, 4K for conversation history (summarized if necessary), 3K for retrieved document chunks (top 3, not top 20), and 3K for the user’s query and output buffer. Total: roughly 12K tokens out of a 128K capacity.
The remaining 116K tokens aren’t wasted. They’re headroom. They’re there for the occasional complex query that genuinely needs more context — a multi-document comparison, a long user message with attached data, an edge case that requires more history. Headroom is a feature, not waste.
This approach requires more engineering than stuffing. You need a retrieval pipeline that’s actually good at finding the right chunks, not just the most chunks. You need summarization logic for conversation history. You need token counting and budget enforcement at the application layer. None of this is free.
But the alternative — paying 10x per request for worse results — is more expensive in every way that matters.
Conversation history is the quiet budget killer
Retrieval gets the attention in architecture discussions. Conversation history is the line item that quietly eats your budget.
In a multi-turn conversation, naively appending every user message and every model response creates a context that grows linearly with conversation length. A 20-turn conversation can easily consume 30-40K tokens of history alone — before you’ve added a single retrieved document.
Most of that history is irrelevant to the current query. The user asked about billing in turn 3, complained about a feature in turn 8, and is now asking about their account settings in turn 20. Turns 3 through 18 are noise for the current request.
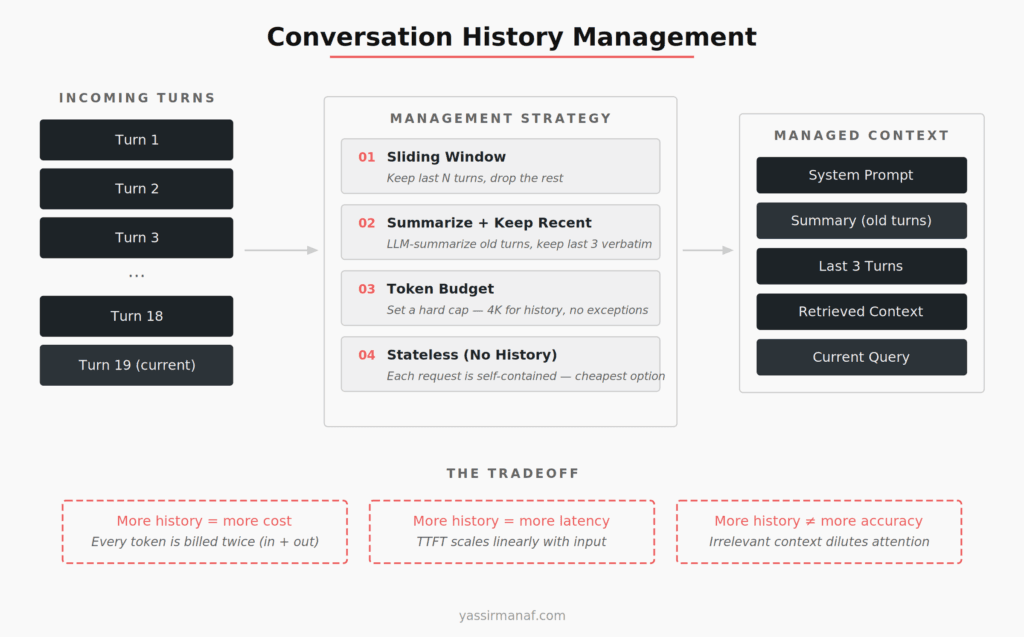
I’ve tested four strategies for managing this, and the right choice depends on your use case.
Sliding window — keep only the last N turns, drop everything else. Simplest to implement. Works well for task-oriented bots where each turn is relatively independent. Falls apart when users reference things they said 10 turns ago and expect the system to remember.
Summarize and keep recent — use a smaller, cheaper model to summarize older conversation turns into a paragraph, then keep the last 3-5 turns verbatim. This is what I use most often. The summary preserves essential context (user’s name, main topic, key decisions made) without the token cost of full history. The summarization call adds 200-400ms but saves thousands of tokens per request downstream.
Hard token budget — set a fixed ceiling for history regardless of conversation length. 4K tokens for history, period. If the conversation is short, you send all of it. If it’s long, you truncate from the oldest. Simple, predictable, and easy to reason about cost-wise.
Stateless — no history at all. Every request is self-contained. Cheapest option, and appropriate more often than people think. If your application is more search-like than conversation-like, history is overhead, not a feature.
On the system I manage now, I use the summarize-and-keep-recent approach. It reduced our average history payload from 28K tokens to 3.8K tokens per request — an 86% reduction — while maintaining conversational coherence on 94% of interactions according to our evaluation rubric.
The cost math that changes your architecture
Context window decisions are cost decisions. This is obvious in theory and consistently ignored in practice.
With GPT-4 Turbo pricing as of early 2025, input tokens cost $10 per million and output tokens cost $30 per million. A 95K-token request costs roughly $0.95 in input alone — before the model generates a single word of response. At 10,000 requests per day, that’s $9,500 daily just for input tokens.
Cut that to 12K tokens per request and your daily input cost drops to $1,200. Same model, same capability, same output quality — often better quality. The savings compound. Over a month, that’s roughly $250,000 in difference.
This is why I wrote about Azure AI cost optimization as a distinct engineering discipline. Context window management is where the largest cost lever sits in most LLM applications, and it’s the one most teams address last — if they address it at all.
The latency impact is equally concrete. Time to first token scales roughly linearly with input length on most providers. A 95K-token input means 4-8 seconds before the user sees anything. A 12K-token input means 1-2 seconds. In a conversational application, that difference is the line between a product that feels responsive and one that feels broken.
Truncation strategies that don’t destroy meaning
When you enforce a token budget, you need a truncation strategy. Naive truncation — cutting from the end or the beginning — destroys meaning in ways that cause silent failures.
I’ve found three approaches that work in production.
Priority-based truncation. Assign priority levels to different content types: system prompt (never truncate), retrieved context (truncate last), conversation history (truncate first). Within each category, use recency as the tiebreaker. This is the most robust approach and the one I default to.
Chunked retrieval with re-ranking. Don’t retrieve 20 chunks and hope the model finds the right ones. Retrieve 20, re-rank with a cross-encoder or a lightweight scoring model, and send only the top 3. The re-ranking step adds 100-200ms but dramatically improves the relevance of what makes it into the context. This connects directly to how I think about prompt engineering as a process — the prompt isn’t just the text you write, it’s the entire context you construct.
Structured context templates. Define a fixed template for every request type your application handles. A billing question gets a different context template than a technical support question. The template specifies exactly which data sources to pull from, how much of each, and in what order. This prevents the “dump everything” reflex because the template physically can’t hold everything.
The common thread: truncation decisions should be made at the application layer, deliberately, before the request reaches the model. If you’re relying on the model to figure out what’s important in a 90K-token context, you’ve already lost.
Why bigger context windows don’t solve this
Model providers keep increasing context window sizes, and every announcement generates excitement. But larger windows don’t change the fundamental economics or the attention dynamics.
A 1-million-token context window is impressive engineering. It’s also a 1-million-token invoice if you fill it. The per-token cost doesn’t decrease with window size — if anything, the models that support larger windows tend to be more expensive.
More importantly, the “lost in the middle” problem doesn’t go away with larger windows. It gets worse. The model’s ability to attend to information at position 500,000 in a million-token context is not something you should bet your production accuracy on.
The teams I’ve seen succeed with LLMs in production don’t use the biggest context window available. They use the smallest context that still produces good results, and they invest the engineering effort to keep it that way.
My context window checklist for production
After working through these problems across multiple systems, I’ve settled on a checklist I run before any LLM feature ships.
Measure your actual token usage. Before optimizing anything, instrument your application to log input token counts per request. Most teams are shocked by how much they’re actually sending. On one system, we discovered that our “lean” prompts averaged 47K tokens because nobody had audited the conversation history logic in six months.
Set a token budget and enforce it. Pick a number — 8K, 12K, 16K — and build your context construction logic to respect it. The budget should be a hard limit in code, not a guideline in documentation.
Separate retrieval from context construction. Retrieve broadly, then filter aggressively. The retrieval step and the context assembly step should be different functions with different objectives. Retrieval casts a wide net. Context assembly is an editor.
Summarize history, don’t accumulate it. For any multi-turn application, implement conversation summarization. The cost of a summarization call is a fraction of the cost of carrying full history across every subsequent request.
Test with minimal context first. Start with the smallest context that produces acceptable results, then add more only when you can measure the improvement. This is the opposite of how most teams work — they start with everything and never get around to trimming.
The context window is the most underengineered part of most LLM applications. Good LLM context window production practice is also the single biggest lever for cost, latency, and quality. Treat it like a production system, not a dump.
Wrestling with context window management in your LLM apps? I’d like to hear what’s worked. Find me on LinkedIn.
Leave a Reply