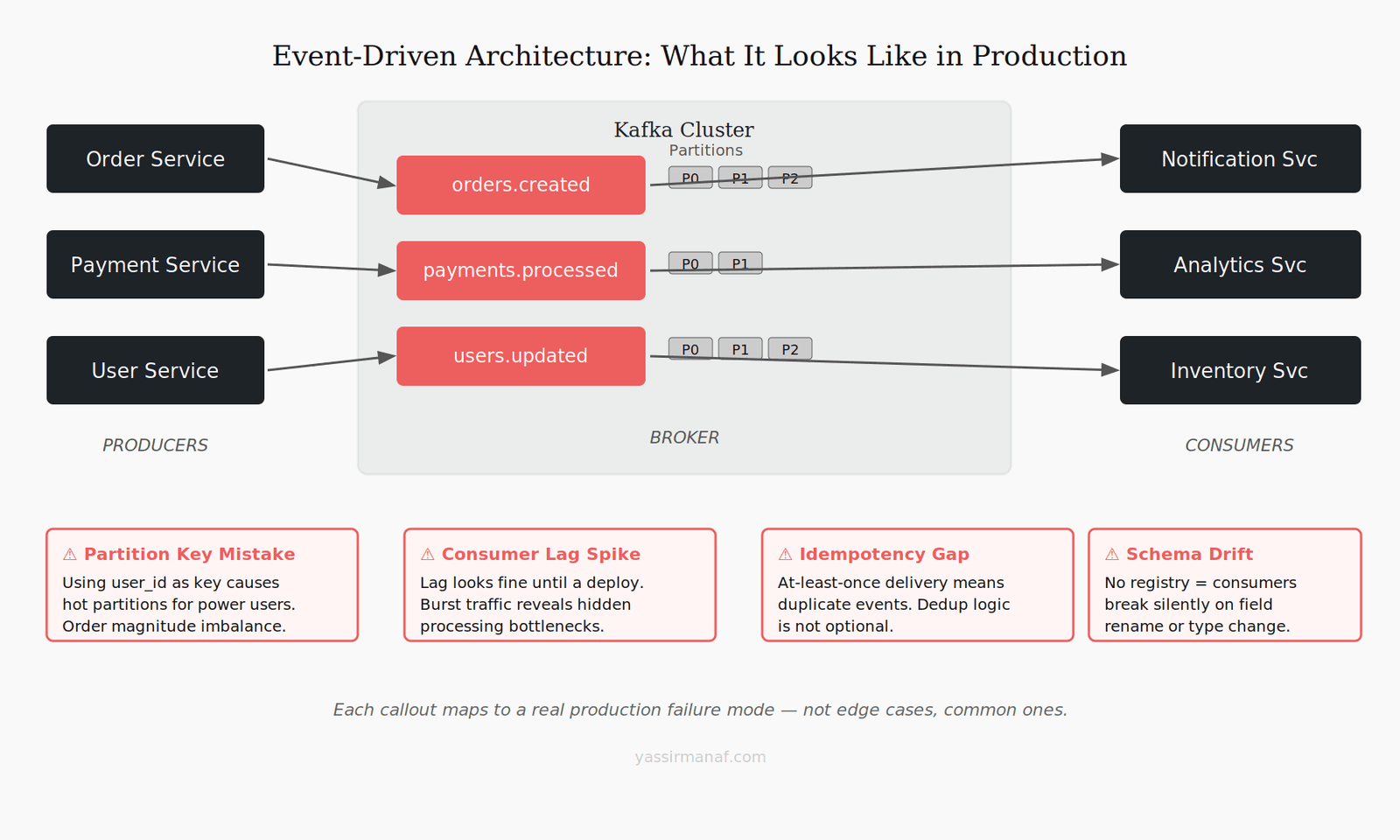
Event driven architecture Kafka implementations always look clean on a whiteboard. Producers emit events, consumers react, services stay decoupled. The diagram fits on a slide and the demo runs perfectly in a sandbox.
Then you put it in production. And the whiteboard lies.
I’ve introduced Kafka into two different production systems. The first time, we got the partition key wrong and spent two months living with the consequences. The second time, we got the partition key right — but walked straight into a schema drift incident that took a full day to diagnose. Both were avoidable. Neither was in the docs.
This article is about the gap between the Kafka tutorial and the Kafka system that wakes you up at 3am. It assumes you know what a topic and a consumer group are. What it covers is everything that comes after.
The partition key decision that haunts you later
The partition key is the most consequential decision in your event driven architecture Kafka setup. Most teams get it wrong the first time — not because they don’t understand it, but because the wrong choice looks completely reasonable until load hits.
The default instinct is to key on whatever feels “natural” — user ID, order ID, entity ID. For even distribution in a test environment, this works fine. In production, natural keys almost always produce hot partitions.
Here’s the failure mode: a SaaS platform keys on user_id. The top 1% of accounts — enterprise customers, automation scripts, power users — generate a disproportionate share of events. All of it lands on the same partition. That partition’s consumer handles ten times the work of the others. The aggregate throughput graph looks healthy. The per-partition lag tells a completely different story, and nobody’s watching per-partition lag.
The fix seems obvious in retrospect — key on something that distributes load, not something that mirrors your domain model. Sometimes that’s a synthetic key, sometimes a composite, sometimes null (round-robin) when per-entity ordering isn’t required.
The harder problem: partition count is fixed at topic creation. You can increase it later, but that breaks ordering guarantees for any consumer relying on key-based routing. Once a topic is live with real consumers, repartitioning requires a migration plan. There’s no quick fix.
A heuristic worth keeping: before you commit to a partition key, find your 10 most active entities and check what percentage of total event volume they generate. If it’s above 30%, your natural key will eventually burn you.
Consumer lag is a feature until it isn’t
Consumer lag gets a bad reputation. Teams monitor it anxiously, set alerts on it, and treat any non-zero value as a problem. That framing misses something important.
Lag is actually one of Kafka’s best properties. A consumer 10,000 messages behind isn’t broken — it’s processing at its own pace, with the full event history available for replay. That’s what separates Kafka from a traditional queue: the log is durable, falling behind is recoverable. It’s a feature.
The problem is when lag shifts from “processing at pace” to “system is overwhelmed.” Those two states look identical on a lag chart.
You usually discover the difference during your first real traffic spike. A deploy, an unexpected integration burst, a campaign nobody told the backend team about — something pushes event production above the consumer’s steady-state processing rate. Lag climbs. If the consumer catches up once load normalizes, you’re fine. If it can’t — if one event now takes longer to process than one event is being produced — you have a compounding problem that gets worse every minute.
The missing piece in most setups is a lag budget: a defined maximum lag at which a consumer is still considered healthy, with a response plan when it’s exceeded. Without it, lag monitoring becomes noise. Engineers learn to ignore the chart because it’s always non-zero, and the one time it actually matters, nobody’s paying attention.
Pair lag with consumer throughput per partition. Lag tells you where you are; throughput tells you which direction you’re moving. Two numbers. That’s enough to act.
Idempotency — you think you’ve handled it, you haven’t
Kafka’s delivery guarantee is at-least-once. That line appears in every Kafka introduction. Most engineers read it, nod, and move on.
At-least-once means your consumer will process the same event more than once. Not in edge cases — regularly. Rebalances, consumer restarts, network blips, offset commit failures. If your cluster is healthy and consumers are running, you will see duplicates.
The standard advice is to make your consumers idempotent. Correct. Also harder than it sounds.
The obvious cases are easy: incrementing a counter isn’t idempotent, upserting a record by ID is. Most engineers nail the obvious cases early. What gets missed is the compound operation — a sequence where each individual step is idempotent, but the full sequence isn’t.
Picture a consumer that: validates an event, writes to a database, calls an external API, then commits the offset. If the API call succeeds but the offset commit fails, the event replays. The DB write and the API call both fire again. If that API is a payment provider, an SMS gateway, a webhook — you’ve just charged a customer twice or sent a duplicate notification. I’ve seen both happen.
The robust fix is an idempotency key that travels with the event, checked before any side-effectful operation. Store processed event IDs in Redis, check at the top of each consumer handler before doing anything else. It’s not glamorous but it holds up.
Exactly-once semantics exist in Kafka (since 0.11) but come with real throughput overhead and implementation complexity. For most systems, at-least-once plus solid idempotency handling is the right call.
Schema evolution and the contract nobody maintains
One of the real strengths of event driven architecture Kafka setups is producer-consumer decoupling. Services deploy independently, scale independently, operate independently. It’s genuinely powerful.
It also creates a contract that nobody officially owns.
A producer owns the schema of the events it emits. When that schema changes — a field renamed, a type changed, a required field made optional — consumers built against the old schema can break silently. No compiler error. No immediate runtime exception. Just a downstream service quietly corrupting its state because it’s receiving events in a shape it wasn’t written to handle.
I’ve watched a field rename take down a consumer six hours after a deploy, in a part of the system nobody connected to the change. The producer team had no idea. The schema change was in a comment in a PR description. That was the entire change management process.
The solution is a schema registry. Confluent Schema Registry is the standard — Avro, JSON Schema, Protobuf, backward/forward/full compatibility rules enforced at publish time. An incompatible change gets rejected before it reaches consumers.
Yes, it’s more infrastructure. Yes, it’s more process. It also eliminates a whole category of incident that’s genuinely painful to diagnose after the fact — especially at 2am, after a deploy that went out six hours ago.
If a registry isn’t viable early on, at minimum: document schemas explicitly, and require a review on any event type change. Manual beats nothing.
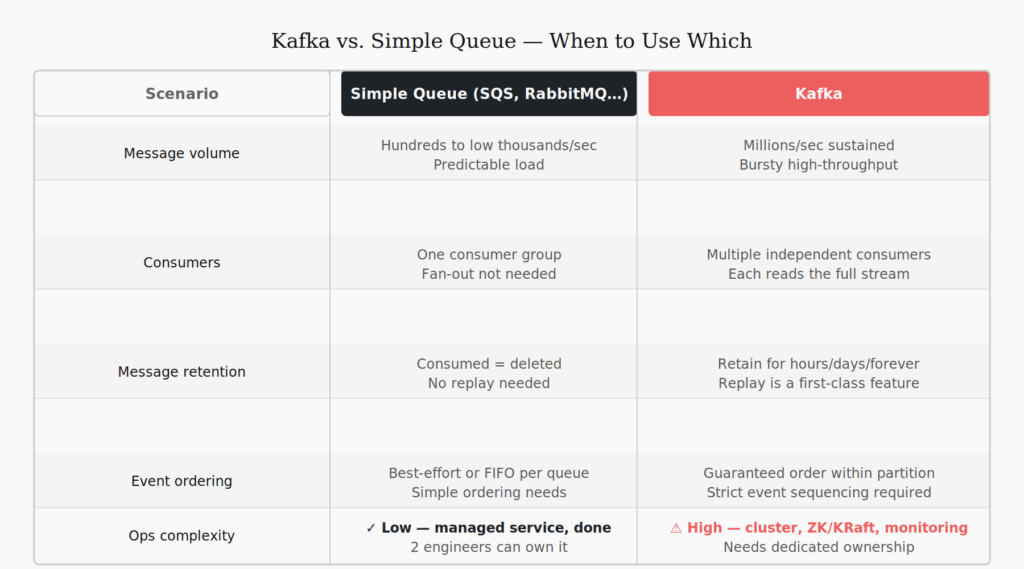
When to use Kafka and when a simple queue is enough
Most teams ask this question after they’ve already adopted Kafka. They should ask it before.
Kafka is a distributed commit log. It’s built for high-volume event streams, multi-consumer fan-out, event replay, and cases where the log itself has business value beyond message delivery. That’s a specific set of requirements — not a general-purpose messaging layer.
If you’re sending a welcome email when a user signs up, you don’t need Kafka. SQS, RabbitMQ, Azure Service Bus — any managed queue delivers that reliably, with a fraction of the operational footprint.
The trap is treating Kafka as the universal answer because it’s already in the stack. Once it’s present for legitimate high-throughput use cases, there’s gravity toward routing everything through it. The result is operational complexity applied to problems that don’t need it.
Use a simple queue when you have one consumer per message type, don’t need replay, volume is predictable, and you want minimal ops overhead.
Use Kafka when multiple independent consumers need the same stream, you need to replay events, throughput is sustained and high, or the event log itself is a business asset.
Running both isn’t an architecture failure — it’s matching tools to problems. Most real systems need both.
The honest verdict on event driven architecture with Kafka
Event driven architecture isn’t a default. It’s a deliberate choice with real operational costs: partition management, consumer group coordination, lag monitoring, schema governance, idempotency discipline.
Worth it when the benefits apply. Overhead when they don’t.
The teams that get lasting value from a Kafka-backed architecture are the ones who introduced it to solve a specific problem and let the scope grow from there. The teams that struggle adopted it as a pattern first and spent months building the scaffolding that should have come before the adoption decision.
If you’re evaluating Kafka right now: start with the question, not the architecture. Kafka’s often the right answer. It just has to earn that through fit, not familiarity.
The whiteboard will always look clean. Production is where the real decisions get made.
Hit one of these failure modes in production? I’d genuinely like to hear how your team handled it. Find me on LinkedIn.
Leave a Reply