Every RAG production demo works. You load a PDF, embed it, ask a question, get a surprisingly good answer. It feels like magic. You show it to a stakeholder and they immediately want to ship it.
Then you try to build the real thing.
The demo worked because you controlled everything — the document, the question, the evaluation. You asked a question you knew the answer to, from a document you’d just read, in a clean environment. RAG production doesn’t work like that. Production means messy documents, unpredictable queries, users who don’t phrase things the way you expect, and failures that are silent enough that nobody notices until someone complains.
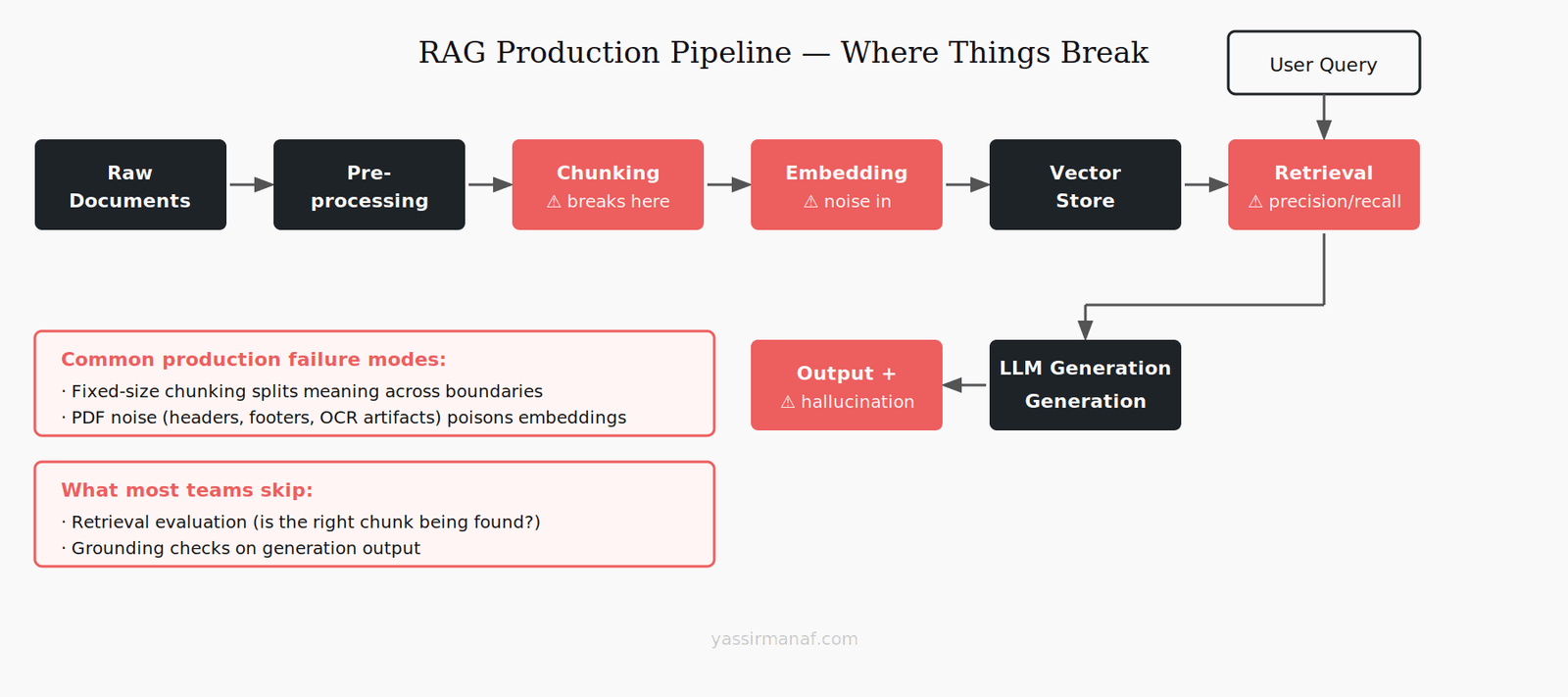
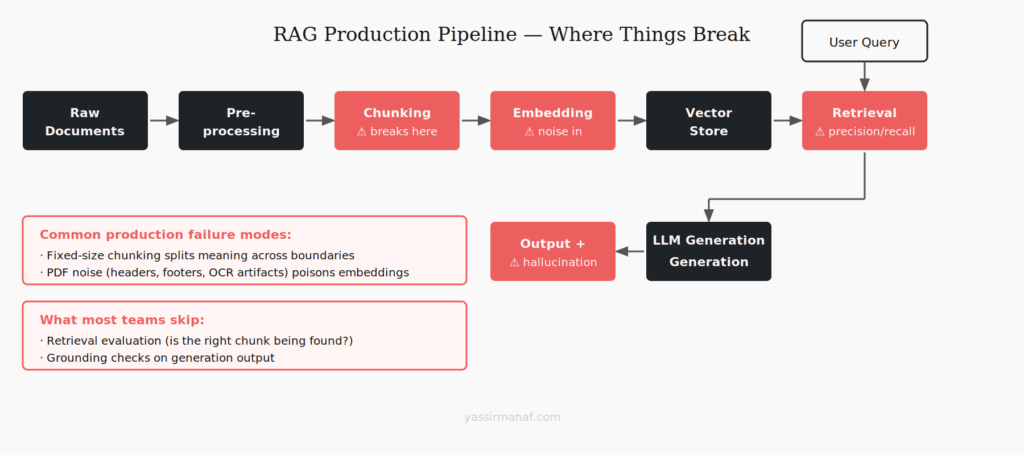
RAG is not a feature you add. It’s a system you build. And most of the hard parts aren’t in the retrieval — they’re in everything around it.
Chunking is not a solved problem
The first thing most RAG tutorials do is split documents into chunks. Fixed size, maybe with some overlap, move on. It takes three lines of code and feels like a solved problem.
It isn’t.
Chunking is where most RAG production systems quietly break. The chunk is the unit your retrieval operates on — whatever ends up in the chunk is what gets sent to the LLM as context. If the chunk cuts in the wrong place, the answer isn’t in the retrieved context. The LLM either hallucinates or says it doesn’t know. Neither is acceptable when users are relying on the system for real information.
Fixed-size chunking is fast and simple. It’s also indifferent to document structure. A 512-token chunk might cut a table in half, split a definition from its explanation, or include the tail of one section and the start of an unrelated one. The text is there. The meaning isn’t.
A few things that actually help:
Semantic chunking — split on meaningful boundaries (headings, paragraphs, section breaks) rather than token count. More work upfront, better retrieval downstream.
Chunk size tuning — there’s no universal right answer. Smaller chunks retrieve more precisely but lose context. Larger chunks preserve context but dilute the signal. You need to test with your actual documents and actual queries.
Metadata attachment — attach document title, section heading, page number to every chunk. When the retrieval returns a chunk, you want to know where it came from. It also helps the LLM ground its response.
Overlap with intent — overlap isn’t just for safety. If a concept spans a chunk boundary, overlap ensures it’s captured in at least one complete chunk. But blind overlap on everything is waste. Apply it where document structure suggests it’s needed.
The honest version: you’ll get chunking wrong the first time. That’s fine. The problem is thinking it’s done and not revisiting it when retrieval quality is low.
Your embeddings are only as good as your preprocessing
Embeddings are often treated as magical — pass text in, get a vector out, similarity search works. And it does work, within limits. The limit that catches most teams is preprocessing.
What goes into the embedding matters enormously. If your documents are PDFs, you’re almost certainly extracting text with noise: headers, footers, page numbers, watermarks, garbled table text, OCR artifacts if any scanned pages are involved. That noise gets embedded. It dilutes the semantic signal. Retrieval becomes fuzzier than it needs to be.
A few preprocessing steps that are worth the time:
Strip boilerplate — headers, footers, legal disclaimers that appear on every page add nothing to retrieval and pollute the embedding space. Remove them before embedding, not after.
Normalize structure — if documents have inconsistent formatting (some use Roman numerals for sections, some use plain numbers, some use descriptive headings), standardize before chunking. Your embeddings will cluster better.
Handle tables deliberately — most text extractors mangle tables. A table that looks clean in the PDF becomes garbled text that embeds poorly and retrieves worse. Either convert tables to structured prose descriptions or exclude them from the embedding pipeline and handle them separately.
Language matters — if your corpus mixes languages, use a multilingual embedding model or separate pipelines per language. A model trained primarily on English won’t embed Arabic or French text with the same fidelity.
None of this is complex. It’s just preprocessing work that doesn’t show up in the demo because the demo used a clean, well-formatted PDF.
Retrieval precision vs. recall — the trade-off nobody talks about
Most RAG systems are tuned for recall: retrieve more chunks, hope the answer is in there somewhere, let the LLM sort it out. This works in demos. In production it creates a different set of problems.
High recall means more context sent to the LLM. More context means higher cost, higher latency, and — counterintuitively — sometimes worse answers. LLMs can get confused by large amounts of loosely relevant context. The answer you want is in there somewhere, but so is a lot of noise, and the model doesn’t always prioritize correctly.
High precision means fewer chunks retrieved, each more directly relevant. Cheaper, faster, cleaner context. The risk is missing the answer entirely if your similarity threshold is too aggressive.
The right balance depends entirely on your use case. A customer support bot where the answer is almost always in a specific paragraph needs high precision. A research assistant where the answer might require synthesizing across multiple sections needs higher recall.
What most teams skip: actually measuring this. They set a top-k, ship it, and adjust when users complain. A better approach is to build an evaluation set early — 50-100 representative questions with known correct answers — and tune retrieval parameters against it. Not perfect, but much better than flying blind.
Two techniques worth knowing:
Reranking — retrieve a broader set (top-20, top-30), then apply a cross-encoder reranker to reorder by relevance before passing to the LLM. Better precision without sacrificing recall in the retrieval step.
Hybrid search — combine vector similarity with keyword search (BM25). Pure vector search misses exact matches. Pure keyword search misses semantic similarity. Hybrid gets both. Most production RAG systems that’ve been running for a while end up here.
Hallucination control in RAG pipelines
RAG reduces hallucination. It doesn’t eliminate it.
The failure modes are different from a vanilla LLM, but they’re still there. The most common one: the retrieved context is close but not quite right, and the LLM fills the gap confidently. The user gets an answer that’s plausible, partially grounded, and wrong in the specific detail that matters.
A few things that actually help in production:
Explicit grounding instructions — tell the model explicitly to answer only from the provided context, and to say when the answer isn’t there. This sounds obvious. Most prompts don’t do it explicitly enough. The model needs to be told what “I don’t know” looks like in your specific context.
Citation requirements — require the model to cite the specific chunk or document it’s drawing from. This forces grounding behavior and makes hallucinations easier to catch. It also gives users a way to verify.
Confidence thresholds on retrieval — if the top retrieved chunk has low similarity to the query, don’t pass it to the LLM. Return a “I couldn’t find relevant information” response instead. A confident wrong answer is worse than an honest non-answer.
Output validation — for high-stakes use cases, run a second LLM call that checks whether the answer is actually supported by the retrieved context. Expensive but worth it when errors have real consequences.
None of this is foolproof. RAG systems will hallucinate. The goal is to make hallucinations rarer and detectable when they happen.
How to evaluate a RAG system (beyond vibes)
Most RAG evaluation is vibes-based. You ask it some questions, the answers seem reasonable, you ship it. Then someone finds a case where it’s confidently wrong and you realize you had no idea how the system was actually performing.
Evaluation is the part of RAG production work that separates systems that hold up from systems that quietly degrade.
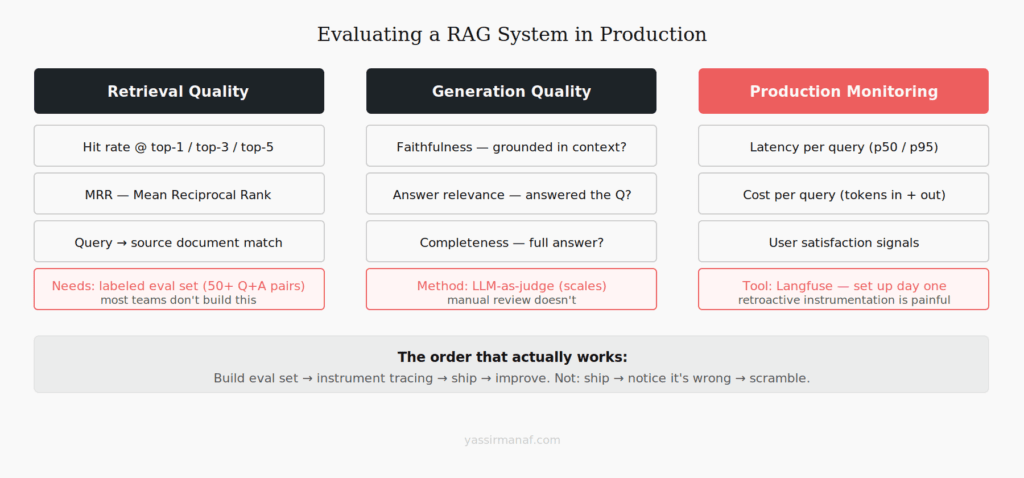
There are two things to evaluate separately: retrieval quality and generation quality. Most teams only check generation, which means retrieval problems are invisible until they cause visible generation failures.
Retrieval evaluation:
- Is the correct document/chunk being retrieved for a given query?
- What’s your hit rate at top-1, top-3, top-5?
- Where does retrieval fail? What types of queries consistently miss?
You need a labeled evaluation set for this — query + expected source document. 50 examples is enough to start. Build it from real user queries once you have them, or from domain experts before launch.
Generation evaluation:
- Is the answer correct given the retrieved context?
- Is the answer grounded in the context (no hallucination)?
- Is the answer complete, or does it miss part of the question?
For generation evaluation, LLM-as-judge works reasonably well — use a separate model call to evaluate each response against a rubric. It’s not perfect but it scales. Manual review doesn’t.
End-to-end: Track a few simple metrics continuously in production: user satisfaction signals (thumbs up/down if you have them), retrieval hit rate on a held-out eval set, response latency, cost per query. Not glamorous, but enough to catch regressions before they become incidents.
Langfuse makes most of this tractable without building custom tooling. Worth setting up early — it’s much harder to instrument retroactively.
RAG is a system, not a feature
The demo takes an afternoon. The production system takes months — not because RAG is inherently complex, but because every component has failure modes that only reveal themselves under real load, with real documents, from real users.
Chunking that worked on your test PDFs breaks on the customer’s scanned contracts. Embeddings that retrieved well on clean text degrade on mixed-language documents. Retrieval that worked for known query patterns struggles with the way users actually phrase things.
None of this is a reason not to build RAG systems. They’re genuinely useful and the tooling is good enough now that a small team can ship something real. But treat it like a system — with evaluation, observability, and an improvement loop — not a feature you add once and consider done.
The teams that ship RAG that actually works in production are the ones that built the evaluation infrastructure first. Everything else followed from there.
What’s the hardest part of your RAG system in production? I’m curious what others are hitting. Find me on LinkedIn.
Leave a Reply